
A continuación se presentan las fórmulas usadas para desarrollar la teoría del Modelo Clásico de Regresión Lineal (MCRL), acompañadas por su sintaxis en R de forma respectiva.
También pudiera interesarte
Medias
Media de la variable X:
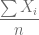
m.X <- sum(X)/length(X)
# o también
m.X <- mean(X)
Media de la variable Y:

m.Y <- sum(Y)/length(Y)
# o también
m.Y <- mean(Y)
Estimadores
Pendiente

beta2 <- sum((X - m.X)*(Y - m.Y))/sum((X - m.X)^2)
Intercepto

beta1 <- m.Y - beta2*m.X
Residuos

res <- Y - Y.e

SCR <- sum(res^2)

SCR <- sum((Y-Y.e)^2) - (sum((X-m.X)*(Y-m.Y)))^2/sum((X-m.X)^2)
Anuncios
Varianza y Error Estándar

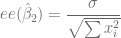
var.beta1 <- sigma2.e*sum( X^2 )/(length(X) * sum( (X-m.X)^2 ))
ee.beta1 <- sqrt(var.beta1)


var.beta1 <- sigma2.e*sum( X^2 )/(length(X) * sum( (X-m.X)^2 ))
ee.beta1 <- sqrt(var.beta1)

sigma2.e <- SCR/(lenght(X)-2)

ee.e <- sqrt(sigma2.e)
Anuncios
Covarianza

cov.b1b2 <- -m.X (sigma2.e/sum((X-m.X)^2))
Bondad de Ajuste

r2 <- sum((Y.e - m.Y)^2)/sum((Y - m.Y)^2)

r2 <- 1 - sum((Y - Y.e)^2)/sum((Y - m.Y)^2)

r2 <- (sum((X-m.X)*(Y-m.Y))^2/(sum((X - m.X)^2)*sum((Y - m.Y)^2))

r <- sum((X-m.X)*(Y-m.Y))/sqrt(sum((X - m.X)^2)*sum((Y - m.Y)^2))
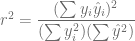
r2 <- (sum(Y-m.Y)*(Y-Y.e))^2/(sum((Y - m.Y)^2)*sum((Y - Y.e)^2))
Anuncios
Estadísticos
Estadístico F
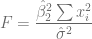
F.c <- beta2^2 * sum((X-m.X)^2)/sigma2.e
#p-value de F.c
pf(F.c,1,length(X)-2,lower.tail = F)
Estadístico t
# Dos colas
qt(alpha/2,df=length(X)-2,lower.tail = FALSE)
# Una cola
qt(alpha,df=length(X)-2,lower.tail = FALSE)
Estadístico chi cuadrado 
# Cola izquierda
qchisq(alpha/2,df=length(X)-2,lower.tail = FALSE)
# Cola derecha
qchisq(1-alpha/2,df=df=length(X)-2,lower.tail = FALSE)
Anuncios
Intervalos de Confianza
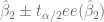
li.beta2 <- beta2 - qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.beta2
ls.beta2 <- beta2 + qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.beta2

li.beta1 <- beta1 - qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.beta1
ls.beta1 <- beta1 + qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.beta1
![P \left[ (n-2) \dfrac{\hat{\sigma}^2}{\chi^2_{\alpha/2}} \leq \sigma^2 \leq (n-2) \dfrac{\hat{\sigma}^2}{\chi^2_{1-\alpha/2}} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%28n-2%29+%5Cdfrac%7B%5Chat%7B%5Csigma%7D%5E2%7D%7B%5Cchi%5E2_%7B%5Calpha%2F2%7D%7D+%5Cleq+%5Csigma%5E2+%5Cleq+%28n-2%29+%5Cdfrac%7B%5Chat%7B%5Csigma%7D%5E2%7D%7B%5Cchi%5E2_%7B1-%5Calpha%2F2%7D%7D+%5Cright%5D+%3D+1-%5Calpha+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
li.sigma2 <- (length(escolaridad)-2)*sigma2.e/qchisq(alpha/2,df=length(escolaridad)-2,lower.tail=F)
ls.sigma2 <- (length(escolaridad)-2)*sigma2.e/qchisq(1-alpha/2,df=length(escolaridad)-2,lower.tail=F)
Anuncios
Predicción

latex Y.0 <- beta1 + beta2*X.0
Varianza de la Predicción Media
![var(\hat{Y}_0) = \sigma^2 \left[ \dfrac{1}{n} + \dfrac{(X_0 - \overline{X})^2}{\sum x_i^2} \right]](https://s0.wp.com/latex.php?latex=var%28%5Chat%7BY%7D_0%29+%3D+%5Csigma%5E2+%5Cleft%5B+%5Cdfrac%7B1%7D%7Bn%7D+%2B+%5Cdfrac%7B%28X_0+-+%5Coverline%7BX%7D%29%5E2%7D%7B%5Csum+x_i%5E2%7D+%5Cright%5D+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
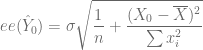
varm.Y.0 <- sigma2.e*(1/length(X)+(X.0-m.X)^2/sum((X-m.X)^2))
eem.C.0 <- sqrt(varm.C.0)
Intervalo de Confianza de la Predicción Media
![P \big[ \hat{\beta}_1 + \hat{\beta}_2 X_0 - t_{\alpha/2} ee(\hat{Y}_0) \leq \beta_1 + \beta_2 X_0 \leq \hat{\beta}_1 + \hat{\beta}_2 X_0 + t_{\alpha/2} ee(\hat{Y}_0) \big] = 1 - \alpha](https://s0.wp.com/latex.php?latex=P+%5Cbig%5B+%5Chat%7B%5Cbeta%7D_1+%2B+%5Chat%7B%5Cbeta%7D_2+X_0+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7BY%7D_0%29+%5Cleq+%5Cbeta_1+%2B+%5Cbeta_2+X_0+%5Cleq+%5Chat%7B%5Cbeta%7D_1+%2B+%5Chat%7B%5Cbeta%7D_2+X_0+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7BY%7D_0%29+%5Cbig%5D+%3D+1+-+%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
li.C.0 <- beta1 + beta2*X.0 - qt(0.025,df=length(X)-2,lower.tail = FALSE)*eem.C.0
ls.C.0 <- beta1 + beta2*X.0 + qt(0.025,df=length(X)-2,lower.tail = FALSE)*eem.C.0
Varianza de la Predicción Individual
![var(Y_0 - \hat{Y}_0) = E[Y_0 - \hat{Y}_0]^2 = \sigma^2 \left[ 1 + \dfrac{1}{n} + \dfrac{(X_0 - \overline{X})^2}{\sum x_i^2} \right]](https://s0.wp.com/latex.php?latex=var%28Y_0+-+%5Chat%7BY%7D_0%29+%3D+E%5BY_0+-+%5Chat%7BY%7D_0%5D%5E2+%3D+%5Csigma%5E2+%5Cleft%5B+1+%2B+%5Cdfrac%7B1%7D%7Bn%7D+%2B+%5Cdfrac%7B%28X_0+-+%5Coverline%7BX%7D%29%5E2%7D%7B%5Csum+x_i%5E2%7D+%5Cright%5D+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
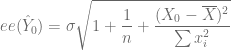
vari.Y.0 <- sigma2.e*(1+1/length(X)+(X.0-m.X)^2/sum((X-m.X)^2))
eei.C.0 <- sqrt(vari.C.0)
Intervalo de Confianza de la Predicción Media
li.C.0 <- beta1 + beta2*X - qt(0.025,df=length(X)-2,lower.tail = FALSE)*eei.C.0
ls.C.0 <- beta1 + beta2*X + qt(0.025,df=length(X)-2,lower.tail = FALSE)*eei.C.0

[…] una de las fórmulas para calcular el coeficiente de determinación , definimos un nuevo valor que está íntimamente […]
Me gustaMe gusta