
Estudiar el comportamiento de los residuos 
También pudiera interesarte
Datos a considerar para los ejemplos
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
| Observación | Salario | Escolaridad |
| 1 | 4.4567 | 6 |
| 2 | 5.77 | 7 |
| 3 | 5.9787 | 8 |
| 4 | 7.3317 | 9 |
| 5 | 7.3182 | 10 |
| 6 | 6.5844 | 11 |
| 7 | 7.8182 | 12 |
| 8 | 7.8351 | 13 |
| 9 | 11.0223 | 14 |
| 10 | 10.6738 | 15 |
| 11 | 10.8361 | 16 |
| 12 | 13.615 | 17 |
| 13 | 13.531 | 18 |
Normalidad
El modelo clásico de regresión lineal normal supone que cada 
- Media:
- Varianza:
- Covarianza:
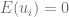


Estos supuestos se expresan en forma más compacta como

Donde el símbolo 

Esta verificación se pude hacer de dos formas: Gráficamente o Estadísticamente.
Gráficamente
Histograma
Podemos graficar un histograma recurriendo a la instrucción hist() para hacer un histograma representando las frecuencias, entonces si previamente hemos definido el modelo lineal usando la instrucción lm() usamos la siguiente sintaxis:
hist(lm(Y~X)$residuals)Aunque si queremos ver un histograma representando la densidad, incorporamos la opción prob = TRUE en la instrucción hist() y más aún, si queremos representar sobre nuestro histograma la línea de densidad, recurrimos a la instrucción line() en conjunto con la instrucción density() usando la siguiente sintaxis:
hist(lm(Y~X)$residuals,prob = TRUE)
lines(density(lm(Y~X)$residuals))Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos generar un histograma de los residuos usando la siguiente sintaxis:
hist(se.lm$residuals,prob = TRUE)
lines(density(se.lm$residuals))Al ejecutar esta instrucción obtenemos el gráfico que estamos buscando:

El gráfico de barras que representa el histograma no demuestra de forma concreta una distribución normal y aunque la línea pareciera dibujar una especie de campana con una protuberancia en el lado izquierdo, no podemos hacer una conclusión fehaciente, así que también se deben llevar a cabo pruebas estadísticas.
Normal QQ-Plot
El QQ-Plot se traduce como el Diagrama de Cuantil-Cuantil y es un diagrama de dispersión que permite comparar distribución de probabilidades. Una gráfica Q-Q es una gráfica de dispersión creada al graficar dos conjuntos de cuantiles entre sí. Si ambos conjuntos de cuantiles provienen de la misma distribución, deberíamos ver los puntos formando una línea que es aproximadamente recta.
Es decir, al comparar la distribución de probabilidad normal con la distribución de probabilidad de los residuos de nuestro modelo lineal, si estos forman una línea recta, este es un indicador de que los residuos están distribuidos de forma normal.
Este gráfico se puede generar con usando la instrucción plot() sobre el modelo lineal, que genera cuatro gráficos pero en este caso nos interesará sólo uno de ellos, el 2:
plot(lm(Y~X),2)Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos generar un histograma de los residuos usando la siguiente sintaxis:
plot(lm(salario~escolaridad),2)Al ejecutar esta instrucción obtenemos el gráfico que estamos buscando:

Aunque no de forma precisa, podemos notar que el diagrama de dispersión pareciera ajustarse a la recta indentidad, representada con una línea punteada, por lo que este gráfico sugiere que sí hay una distribución normal de los residuos. Sin embargo, no podemos hacer una conclusión fehaciente, así que también se deben llevar a cabo pruebas estadísticas.
Estadísticamente
Jarque–Bera test
La Prueba de Jarque-Bera partiendo del hecho de que una distribución normal tiene coeficiente de asimetría igual a 0 y Curtosis igual a 3. Estos dos elementos se miden a partir de los residuos de nuestro modelo lineal usando la siguientes formulas, respectivamente:
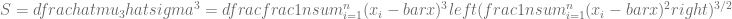

Definiendo así el coeficiente de asimetría (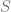
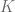

Si el valor del estadístico es igual a cero, este es un indicador de que la distribución de los residuos es normal. Más aún, El estadístico de Jarque-Bera se distribuye asintóticamente como una distribución chi cuadrado con dos grados de libertad y puede usarse para probar la hipótesis nula de que los datos pertenecen a una distribución normal. La hipótesis nula es una hipótesis conjunta de que la asimetría y el exceso de curtosis son nulos (asimetría = 0 y curtosis = 3)
Para llevar a cabo esta prueba en R, se carga a la librería tseries y en ella recurrimos a la instrucción jarque.bera.test() usando la siguiente sintaxis:
library(tseries)
jarque.bera.test(lm(Y~X)$residuals)Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos llevar a cabo la Prueba de Jarque-Bera, para esto, usamos la siguiente sintaxis:
library(tseries)
jarque.bera.test(se.lm$residuals)Al ejecutar esta instrucción obtenemos los resultados de la prueba, donde nos interesará de forma particular que el p-value es igual a 0.6608, notando que este valor es mayor que 0.05, entonces no rechazamos la hipótesis nula y podemos asumir que el coeficiente de asimetría es igual a cero y que la curtosis es igual tres, por lo que asumimos que los residuos tienen una distribución normal.
En su consola debería aparecer:
> library(tseries)
> jarque.bera.test(se.lm$residuals)
Jarque Bera Test
data: se.lm$residuals
X-squared = 0.8287, df = 2, p-value = 0.6608
Bibliografía complementaria
- Linear Regression Example in R using lm() Function – Learn by Marketing. (2021). Learnbymarketing.com. Retrieved 3 June 2021, from http://www.learnbymarketing.com/tutorials/linear-regression-in-r/
- Diseño Experimental. (2021). Red.unal.edu.co. Retrieved 4 June 2021, from http://red.unal.edu.co/cursos/ciencias/2007315/html/un6/cont_05_66.html
- Understanding Q-Q Plots | University of Virginia Library Research Data Services + Sciences. (2015). Data.library.virginia.edu. Retrieved 4 June 2021, from https://data.library.virginia.edu/understanding-q-q-plots/
- Histogram + Density Plot Combo in R | R-bloggers. (2012). R-bloggers. Retrieved 4 June 2021, from https://www.r-bloggers.com/2012/09/histogram-density-plot-combo-in-r/
- Test de Jarque-Bera – Wikipedia, la enciclopedia libre. (2021). Es.wikipedia.org. Retrieved 4 June 2021, from https://es.wikipedia.org/wiki/Test_de_Jarque-Bera
Observaciones
Las pruebas expuestas en esta lección sirven para hacer algunas aseveraciones y su carácter didáctico es importante para entender el análisis de residuos, sin embargo, Jeffrey Wooldridge en su cuenta de twitter hace algunas observaciones que deben ser consideradas al hacer trabajos más especializados.
