
Estudiar el comportamiento de los residuos 
También pudiera interesarte
Datos a considerar para los ejemplos
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
| Observación | Salario | Escolaridad |
| 1 | 4.4567 | 6 |
| 2 | 5.77 | 7 |
| 3 | 5.9787 | 8 |
| 4 | 7.3317 | 9 |
| 5 | 7.3182 | 10 |
| 6 | 6.5844 | 11 |
| 7 | 7.8182 | 12 |
| 8 | 7.8351 | 13 |
| 9 | 11.0223 | 14 |
| 10 | 10.6738 | 15 |
| 11 | 10.8361 | 16 |
| 12 | 13.615 | 17 |
| 13 | 13.531 | 18 |
Residuos independientes
Una vez que hemos planteado un modelo lineal, es importante que los residuos alberguen toda esa información que no podemos explicar con la variable independiente, es por esta razón que uno de los supuestos del Modelo Clásico de Regresión Lineal propone que los residuos deben ser independientes de la variable independiente.
Considerando el caso en que la regresora es estocástica, los valores que toma la variable independiente 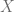
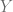


Para calcular en R la covarianza de entre la variable independiente
cov(X,Y-lm(Y~X)$fitted.values)Donde, Y.e es la variable que almacena los valores estimados de
cov(X,lm(Y~X)$residuals)Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos calcular la covarianza entre la variable independiente Escolaridad y los residuos lm(salario~escolaridad)$residuals, para esto, usamos la siguiente sintaxis:
cov(escolaridad,lm(salario~escolaridad)$residuals)Al ejecutar esta instrucción obtenemos la covarianza que buscamos, que en este caso es igual a 2.276825e-18, notando que este valor es prácticamente cero, concluimos que los residuos son independientes de la variable Escolaridad.
En su consola debería aparecer:
> cov(escolaridad,se.lm$residuals)
[1] 2.276825e-18
Bibliografía complementaria
- Linear Regression Example in R using lm() Function – Learn by Marketing. (2021). Learnbymarketing.com. Retrieved 3 June 2021, from http://www.learnbymarketing.com/tutorials/linear-regression-in-r/
- Diseño Experimental. (2021). Red.unal.edu.co. Retrieved 4 June 2021, from http://red.unal.edu.co/cursos/ciencias/2007315/html/un6/cont_05_66.html
