
El análisis de regresión sienta la base para los estudios econométricos y a su vez, estos se fundamentan formulando modelos lineales con dos variables: una independiente y otra dependiente; este tipo de modelos definen rectas, es decir, aquellos que se expresan de la siguiente forma:
También pudiera interesarte
Linealidad
Al mencionar la linealidad en una relación entre variables, siempre es importante especificar respecto a qué elemento de la relación, es dicha relación, lineal. Formalmente, diremos que una relación es lineal respecto a un elemento de la ecuación, si dicho elemento no está siendo multiplicada por sí mismo o si permanece inalterado por alguna función en la expresión, por ejemplo, la siguiente ecuación

Es una ecuación lineal respecto respecto la variable 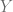

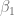
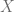
La linealidad respecto a los parámetros representa una base en la que se fundamentan los Modelos Lineales que estudiaremos. Es por esto que, usualmente, el término regresión lineal hace referencia a la linealidad de los parámetros. Por lo tanto, puede o no ser lineal en las variables.
El Modelo de Regresión Lineal
Todo estudio de índole estadístico está sometido a un error de aproximación y la econometría no escapa de esta característica, de forma que, al efectuar un censo poblacional, se puede estimar un modelo definido por la Función de Regresión Poblacional (FRP), expresado de la siguiente manera:
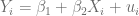
Sin embargo, llevar a cabo un censo puede resultar costoso en todos los aspectos, es por esto que se recurre a muestras poblacionales, a partir de las cuales se puede estimar un modelo definido por la Función de Regresión Muestral (FRM), expresado de la siguiente manera:

Y si bien el objetivo principal del análisis de regresión es estimar la FRP con base en la FRM, siempre se debe tomar en cuenta que: debido a fluctuaciones muestrales, la estimación de la FRP basada en la FRM es, en el mejor de los casos, una aproximación.
Mínimos Cuadrados Ordinarios (MCO)
Entonces, los valores de 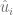
El Método de los Mínimos Cuadrados Ordinarios (MCO) que consiste en considerar, de todos los modelos posibles, el modelo tal que la suma de los cuadrados de los residuos
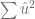
Llevando a cabo los cálculos necesarios para que esto se cumpla, se determina que los valores que estiman a 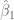

El valor

El valor

Conociendo estas dos expresiones, podemos hacer los cálculos correspondientes en R, pues calculando la media de las variables
m.X <- mean(X)
m.Y <- mean(Y)
beta2 <- sum((X - m.X)*(Y - m.Y))/sum((X - m.X)^2)
beta1 <- m.Y - beta2*m.XEjemplo
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
| Observación | Salario | Escolaridad |
| 1 | 4.4567 | 6 |
| 2 | 5.77 | 7 |
| 3 | 5.9787 | 8 |
| 4 | 7.3317 | 9 |
| 5 | 7.3182 | 10 |
| 6 | 6.5844 | 11 |
| 7 | 7.8182 | 12 |
| 8 | 7.8351 | 13 |
| 9 | 11.0223 | 14 |
| 10 | 10.6738 | 15 |
| 11 | 10.8361 | 16 |
| 12 | 13.615 | 17 |
| 13 | 13.531 | 18 |
Si queremos definir un modelo que describa el salario de una persona en función del nivel de estudio que esta persona tenga, empezamos por definir las variables salario y escolaridad, usando las siguientes instrucciones:
escolaridad <- c(6,7,8,9,10,11,12,13,14,15,16,17,18)
salario <- c(4.4567,5.77,5.9787,7.3317,7.3182,6.5844,7.8182,7.8351,11.0223,10.6738,10.8361,13.615,13.531)
Una vez definidas estas variables, podemos definir nuevas variables para almacenar la media de cada una de ellas:
m.escolaridad <- mean(escolaridad)
m.salario <- mean(salario)Posteriormente, calculamos los estimadores:
beta2 <- sum( (escolaridad-m.escolaridad)*(salario-m.salario) )/sum( (escolaridad-m.escolaridad)^2 )
beta1 <- m.salario - beta2*m.escolaridadAl ejecutar estas instrucciones definimos las variables y podemos ver los valores que cada una de ellas tienen, particularmente la de los estimadores que son las que nos interesan.

Mi recomendación es usar el símbolo de numeral «#» para hacer comentarios en el script y mantener orden en las instrucciones que escribimos o entender porqué las escribimos, les comparto como haría yo estas anotaciones.

Habiendo calculado los valores de los estimadores, concluimos que el modelo lineal determinado por el método de los Mínimos Cuadrados Ordinarios, que estima el comportamiento de los valores expuestos en la Tabla 3.2 es el siguiente:

La instrucción lm
También podemos recurrir a la instrucción lm para definir un modelo lineal, de forma que si queremos definir a la variable
lm(Y ~ X)Note que se ha usado la virguilla (~) para definir la relación entre las dos variables. Entonces, continuando con nuestro ejemplo, podemos definir el modelo lineal que describe el Salario en función de la Escolaridad usando la siguiente sintaxis:
lm(salario ~ escolaridad)Al ejecutar esta instrucción, en la consola deberá aparecer lo siguiente:
> lm(salario ~ escolaridad)
Call:
lm(formula = salario ~ escolaridad)
Coefficients:
(Intercept) escolaridad
-0.01445 0.72410
En su pantalla debería aparecer:


[…] R para introducir a la Econometría: Estimadores MCO […]
Me gustaMe gusta