
Análisis de Regresión con Dos Variables
A continuación encontrarán el script que se ha desarrollado durante las clases de Econometría 1 para el tema de Análisis de Regresión con Dos Variables. Puede copiar y pegar este script en un editor de R para correr las instrucciones junto a las notas de clases.
#----Econometría 1 - Prof. Anthonny Arias----#
#--Limpiamos nuestro espacio de trabajo--#
rm(); rm(list=ls())
cat("\014")
# Definimos la variable escolaridad y su media.
# Para esto, usamos la instrucción c() para definir vector.
# Y usamos la instrucción mean() para definir la media.
escolaridad <- c(6,7,8,9,10,11,12,13,14,15,16,17,18)
m.escolaridad <- mean(escolaridad)
# Definimos la variable salario y su media.
salario <- c(4.4567,5.77,5.9787,7.3317,7.3182,6.5844,7.8182,7.8351,11.0223,10.6738,10.8361,13.615,13.531)
m.salario <- mean(salario)
# Hacemos un gráfico de dispersión de estas dos variables.
plot(escolaridad,salario)
# Una vez obtenidos estos valores, podemos calcular los estimadores beta1 y beta2.
beta2 <- sum( (escolaridad-m.escolaridad)*(salario-m.salario) )/sum( (escolaridad-m.escolaridad)^2 )
beta2
beta1 <- m.salario - beta2*m.escolaridad
beta1
# Calculamos los valores estimados del salario.
salario.e <- beta1 + beta2*escolaridad
salario.e
# Calculamos los residuos.
residuos <- salario - salario.e
residuos
# Calculamos la var.e.
var.e <- sum( (residuos)^2 )/(length(salario)-2)
var.e
# Caculamos el error estándar, aplicando la raíz cuadrada a la var.e.
error.s <- sqrt(var.e)
error.s
# Calculamos la var.e de beta2
v.beta2 <- var.e/sum( (escolaridad-m.escolaridad)^2 )
v.beta2
# Calculamos el error estándar de beta2
es.beta2 <- sqrt(v.beta2)
es.beta2
# Para calcular el intervalo de confianza de beta2, consideramos t=1.7959
li.beta2 <- beta2 - qt(0.975,df=length(escolaridad)-2)*es.beta2
li.beta2
ls.beta2 <- beta2 + qt(0.975,df=length(escolaridad)-2)*es.beta2
ls.beta2
# Calculamos la var.e de beta1.
v.beta1 <- var.e*sum( escolaridad^2 )/(length(escolaridad) * sum( (escolaridad-m.escolaridad)^2 ))
v.beta1
# Calculamos el error estándar de beta1
es.beta1 <- sqrt(v.beta1)
es.beta1
# Para calcular el intervalo de confianza de beta1, consideramos t=1.7959
li.beta1 <- beta1 - qt(0.975,df=length(escolaridad)-2)*es.beta1
li.beta1
ls.beta1 <- beta1 + qt(0.975,df=length(escolaridad)-2)*es.beta1
ls.beta1
# Para hacer la prueba de hipótesis bilateral, determinamos el t-calculado.
t.c <- (beta2-0.70)/es.beta2
t.c # Como t.c está fuera del intervalo (-2.201,2.201) entonces rechazamos la hipótesis nula.
qt(0.025,df=length(escolaridad)-2)
qt(0.975,df=length(escolaridad)-2)
# Para hacer la prueba de hipótesis unilateral, determinamos el t-calculado.
t.c <- (beta2-0.50)/es.beta2
t.c # Como t.c está fuera del intervalo (-2.201,2.201) entonces rechazamos la hipótesis nula.
qt(0.95,df=length(escolaridad)-2)
# Calculamos ahora, el intervalo de confianza para chi-cuadrado
li.var.e <- (length(escolaridad)-2)*var.e/qchisq(0.975,df=11)
li.var.e
ls.var.e <- (length(escolaridad)-2)*var.e/qchisq(0.025,df=11)
ls.var.e
# Como la hipótesis nula indica que la varianza es igual a 0.6, entonces no rechazamos esta hipótesis.
# Podemos también llevar a cabo esta prueba con el estadístico chi-cuadrado. Para esto, calculamos el estadístico chi-cuadrado.
chi.c <- (length(escolaridad)-2)*var.e/0.6
chi.c
li.chi <- qchisq(0.025,df=df=length(escolaridad)-2)
li.chi
ls.chi <- qchisq(0.975,df=df=length(escolaridad)-2)
ls.chi
# Éste está dentro del intervalo [ qchisq(0.025,df=df=length(escolaridad)-2) ; qchisq(0.025,df=df=length(escolaridad)-2) ], por lo tanto, no se rechaza H0.
# Calculamos la suma de los cuadrados explicada.
SCE.escolaridad <- beta2^2*sum( (escolaridad-m.escolaridad)^2 )
SCP.escolaridad <- SCE.escolaridad/1
SCP.escolaridad
# Calculamos la suma de los cuadrados de los residuos.
SCR.residuos <- sum(residuos^2)
SCP.residuos <- SCR.residuos/(length(escolaridad)-2)
SCP.residuos
# Calculamos la suma de los cuadrados totales.
SCT.salarios <- sum( (salario-m.salario)^2 )
SCP.salarios <- SCT.salarios/(length(salario)-1)
SCP.salarios
# Calculamos ahora el valor F (F calculado).
F.c <- SCP.escolaridad/SCP.residuos
F.c
# Calculamos el p-value (valor-p) para este F calculado.
pf(F.c,1,length(escolaridad)-2,lower.tail = F)
# Verificamos que se cumple el teorema
t.c <- (beta2-0)/es.beta2
t.c
t.c^2
F.c
# Predicción de la Media
escolaridad.0 <- 20
salario.0 <- beta1 + beta2*escolaridad.0
salario.0
# Calculamos la varianza de la predicción.
varm.salario.0 <- var.e*(1/length(escolaridad)+(escolaridad.0-m.escolaridad)^2/sum((escolaridad-m.escolaridad)^2))
varm.salario.0
# Calculamos ahora el error estándar.
eem.salario.0<- sqrt(varm.salario.0)
eem.salario.0
# Calculamos el intervalo de confianza para salario.0
li.salario.0 <- beta1 + beta2*escolaridad.0 - qt(0.025,df=length(escolaridad)-2,lower.tail = FALSE)*eem.salario.0
li.salario.0
ls.salario.0 <- beta1 + beta2*escolaridad.0 + qt(0.025,df=length(escolaridad)-2,lower.tail = FALSE)*eem.salario.0
ls.salario.0
# Predicción Individual
# Calculamos la varianza de la predicción.
vari.salario.0 <- var.e*(1+1/length(escolaridad)+(escolaridad.0-m.escolaridad)^2/sum((escolaridad-m.escolaridad)^2))
vari.salario.0
# Calculamos ahora el error estándar.
eei.salario.0<- sqrt(vari.salario.0)
eei.salario.0
# Calculamos el intervalo de confianza para salario.0
li.salario.0 <- beta1 + beta2*escolaridad.0 - qt(0.025,df=length(escolaridad)-2,lower.tail = FALSE)*eei.salario.0
li.salario.0
ls.salario.0 <- beta1 + beta2*escolaridad.0 + qt(0.025,df=length(escolaridad)-2,lower.tail = FALSE)*eei.salario.0
ls.salario.0
#----Análisis de Residuos----#
#--Análisis de Correlación--#
# Gráfico de dispersión para los residuos.
plot(residuos)
# Hacemos la gráfica de la función de autocorrelación.
# Si todaslas barras están por debajo de las líneas azules, esto indica que no hay autocorrelación.
# https://www.reddit.com/r/AskStatistics/comments/5kiix2/interpret_acfpacf_dataplots_in_r/
acf(residuos)
# Hacemos la prueba de Durbin–Watson, que establece como hipótesis nula que el coeficiente de correlación es igual a cero.
# El estadístico de Durbin–Watson igual a dos indica que no hay autocorrelación.
# https://en.wikipedia.org/wiki/Durbin%E2%80%93Watson_statistic
library("lmtest")
dwtest(salario ~ escolaridad)
#--Pruebas de Normalidad--#
# Generamos el histograma de los residuos.
hist(residuos)
plot(density(residuos))
# Gráfica de probabilidad normal
qqnorm(residuos, pch = 1, frame = TRUE)
qqline(residuos, col = "steelblue", lwd = 2)
# También se puede llevar a cabo usando el siguiente comando
library("car")
qqPlot(residuos,col.lines="steelblue")
# Prueba de Anderson-Darling.
library(nortest)
ad.test(residuos)
# Prueba de normalidad de Jarque-Bera (JB)
# https://lancebachmeier.com/computing/j-b-test.html
# Esta plantea como hipótesis nula el coeficiente de asimetría igual cero y la curtosis igual a tres.
library(tseries)
jarque.bera.test(residuos)
# Prueba de normalidad de Shapiro-Wilk
# https://stat.ethz.ch/R-manual/R-devel/library/stats/html/shapiro.test.html
# Esta prueba plantea como hipótesis nula que los datos están normalmente distribuídos.
shapiro.test(residuos)

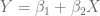

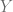 y el parámetro
y el parámetro  , debido a que estos dos elementos permanecen inalterados. Sin embargo, no es lineal respecto al parámetro
, debido a que estos dos elementos permanecen inalterados. Sin embargo, no es lineal respecto al parámetro 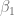 pues este está multiplicado por sí mismo, tampoco es lineal respecto a la variable
pues este está multiplicado por sí mismo, tampoco es lineal respecto a la variable 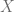 pues esta está alterada por la función logaritmo neperiano.
pues esta está alterada por la función logaritmo neperiano.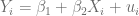

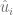 más pequeño posible, sin embargo, no podemos permitir que estos errores se anulen.
más pequeño posible, sin embargo, no podemos permitir que estos errores se anulen.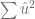
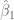 y
y  se calculan de la siguiente forma:
se calculan de la siguiente forma:






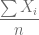





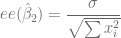









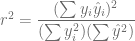
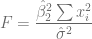

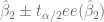

![P \left[ (n-2) \dfrac{\hat{\sigma}^2}{\chi^2_{\alpha/2}} \leq \sigma^2 \leq (n-2) \dfrac{\hat{\sigma}^2}{\chi^2_{1-\alpha/2}} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%28n-2%29+%5Cdfrac%7B%5Chat%7B%5Csigma%7D%5E2%7D%7B%5Cchi%5E2_%7B%5Calpha%2F2%7D%7D+%5Cleq+%5Csigma%5E2+%5Cleq+%28n-2%29+%5Cdfrac%7B%5Chat%7B%5Csigma%7D%5E2%7D%7B%5Cchi%5E2_%7B1-%5Calpha%2F2%7D%7D+%5Cright%5D+%3D+1-%5Calpha+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)

![var(\hat{Y}_0) = \sigma^2 \left[ \dfrac{1}{n} + \dfrac{(X_0 - \overline{X})^2}{\sum x_i^2} \right]](https://s0.wp.com/latex.php?latex=var%28%5Chat%7BY%7D_0%29+%3D+%5Csigma%5E2+%5Cleft%5B+%5Cdfrac%7B1%7D%7Bn%7D+%2B+%5Cdfrac%7B%28X_0+-+%5Coverline%7BX%7D%29%5E2%7D%7B%5Csum+x_i%5E2%7D+%5Cright%5D+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
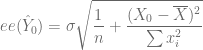
![P \big[ \hat{\beta}_1 + \hat{\beta}_2 X_0 - t_{\alpha/2} ee(\hat{Y}_0) \leq \beta_1 + \beta_2 X_0 \leq \hat{\beta}_1 + \hat{\beta}_2 X_0 + t_{\alpha/2} ee(\hat{Y}_0) \big] = 1 - \alpha](https://s0.wp.com/latex.php?latex=P+%5Cbig%5B+%5Chat%7B%5Cbeta%7D_1+%2B+%5Chat%7B%5Cbeta%7D_2+X_0+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7BY%7D_0%29+%5Cleq+%5Cbeta_1+%2B+%5Cbeta_2+X_0+%5Cleq+%5Chat%7B%5Cbeta%7D_1+%2B+%5Chat%7B%5Cbeta%7D_2+X_0+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7BY%7D_0%29+%5Cbig%5D+%3D+1+-+%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
![var(Y_0 - \hat{Y}_0) = E[Y_0 - \hat{Y}_0]^2 = \sigma^2 \left[ 1 + \dfrac{1}{n} + \dfrac{(X_0 - \overline{X})^2}{\sum x_i^2} \right]](https://s0.wp.com/latex.php?latex=var%28Y_0+-+%5Chat%7BY%7D_0%29+%3D+E%5BY_0+-+%5Chat%7BY%7D_0%5D%5E2+%3D+%5Csigma%5E2+%5Cleft%5B+1+%2B+%5Cdfrac%7B1%7D%7Bn%7D+%2B+%5Cdfrac%7B%28X_0+-+%5Coverline%7BX%7D%29%5E2%7D%7B%5Csum+x_i%5E2%7D+%5Cright%5D+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
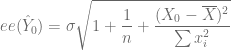

Debe estar conectado para enviar un comentario.