
Introducir a la econometría requiere estudiar de forma minuciosa cada uno de los elementos que permiten el análisis de regresión y si bien podemos calcular cada uno de estos usando las fórmulas que provee la teoría, la idea de usar programas de paquetes estadísticos como R es usar instrucciones que nos permitan hacer este tipo de cálculos de forma automática.
También pudiera interesarte
La instrucción lm()
Si se cuentan con al menos dos variables, digamos 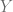
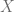
lm(Y ~ x)Al ejecutar esta instrucción se mostrará el valor de 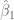

Esta información puede almacenarse en una variable pues a partir de ella obtener información valiosa sobre nuestro modelo. Entonces, para almacenar esta información en una variable, digamos yx.lm, usamos la siguiente sintaxis:
yx.lm <- lm(Y ~ x)Veamos la información básica que podemos obtener definiendo del modelo lineal de esta forma.
coefficients
Podemos observar directamente los coeficientes del modelo lineal haciendo el llamado coefficients a partir de la variable que almacena la información del modelo lineal, para esto, recurrimos el símbolo de dólar $ usando la siguiente sintaxis:
yx.lm$coefficientsresiduals
Podemos observar directamente los residuos del modelo lineal haciendo el llamado residuals a partir de la variable que almacena la información del modelo lineal, para esto, recurrimos el símbolo de dólar $ usando la siguiente sintaxis:
yx.lm$residualsfitted.values
Podemos observar directamente los valores ajustados del modelo lineal, es decir, todos los valores estimados 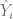
yx.lm$fitted.valuesLa instrucción summary()
Si bien se puede obtener información individual haciendo un llamado a algunos elementos específicos del modelo lineal, una de las herramientas más valiosas que provee R para el análisis regresión lineal es el resumen del modelo pues a partir de él, podemos consultar los siguientes elementos:
Sobre el llamado
- Call – Nos indica la fórmula que define el modelo lineal.
Sobre los residuos
- Min – Mínimo.
- 1Q – Primer cuartil Q1.
- Median – Media (o segundo cuartil Q2)
- 3Q – Tercer cuartil Q3
- Max – Máximo.
Es importante verificar que el valor de la media de los residuos sea cero o esté muy cercano a cero, pues este es uno de los supuestos del Método de los Mínimos Cuadrado Ordinarios (MCO).
Sobre los coeficientes
- Estimate – Estimadores
.
- Std. Error – Error estándar de cada estimador.
- t value – Valor del estadístico
correspondiente a cada estimador.
- Pr(>|t|) – p-value correspondiente la prueba t de cada estimador.
- Signif. codes – Códigos de significancia.
En este caso la prueba t plantea la hipótesis nula 
El valor p o p-value determina la probabilidad exacta de cometer un error tipo I considerando el valor
Para facilitar la interpretación del p-value, se utiliza un código de significancia, notando que
- 0 ‘***’ La probabilidad de cometer un error tipo I es prácticamente nula.
- 0.001 ‘**’ La probabilidad de cometer un error tipo I es de a lo sumo el 0.1%.
- 0.01 ‘*’ La probabilidad de cometer un error tipo I es de a lo sumo el 1%.
- 0.05 ‘.’ La probabilidad de cometer un error tipo I es de a lo sumo el 5%.
- 0.1 ‘ ’ La probabilidad de cometer un error tipo I es de a lo sumo el 1%.
Sobre el error estándar de los residuos
- Residual standard error – Error estándar de estimación o error estándar de la regresión.
Recordando que el error estándar de estimación nos sirve como una medida de bondad de ajuste, es importante verificar que este sea lo más pequeño posible, recordando siempre que este nunca es igual a cero, pues se define a partir de una suma de cuadrados.
Sobre el coeficiente de determinación
- Multiple R-squared – Coeficiente de Determinación (sin ajuste al añadir más variables)
- Adjusted R-squared – Coeficiente de Determinación (con ajuste al añadir más variables)
Es importante añadir que al definir modelos, estos no necesariamente se determinan con dos variables, así que al incluir más variables el coeficiente de determinación que determina Multiple R-squared aumentará a medida que se agregan variables, por otra parte, el coeficiente de determinación que determina Adjusted R-squared será corregido por la cantidad de variables involucradas en el modelo por lo que indica de forma más realista en qué medida las variables independientes (en conjunto) explican a la variable dependiente.
Recordemos que si bien es importante que la variable independiente explique la variable pendiente, el objetivo del análisis de regresión no es que el valor del coeficiente de determinación sea igual a 1.
Sobre el estadístico F
- F-statistic – Estadístico F.
Para el caso de dos variables, la prueba F plantea la hipótesis nula 
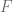
Para el caso de más variables, se plantea una hipótesis conjunta 
El valor p o p-value determina la probabilidad exacta de cometer un error tipo I considerando el valor
Ejemplo
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
| Observación | Salario | Escolaridad |
| 1 | 4.4567 | 6 |
| 2 | 5.77 | 7 |
| 3 | 5.9787 | 8 |
| 4 | 7.3317 | 9 |
| 5 | 7.3182 | 10 |
| 6 | 6.5844 | 11 |
| 7 | 7.8182 | 12 |
| 8 | 7.8351 | 13 |
| 9 | 11.0223 | 14 |
| 10 | 10.6738 | 15 |
| 11 | 10.8361 | 16 |
| 12 | 13.615 | 17 |
| 13 | 13.531 | 18 |
Definimos un modelo lineal que describe el salario en función de la escolaridad con la instrucción lm() y almacenamos esta información en la variable se.lm usando la siguiente sintaxis:
se.lm <- lm(salario ~ escolaridad)Posteriormente, hacemos un resumen de la información que provee este modelo lineal con la instrucción summary() usando la siguiente sintaxis:
summary(se.lm)Al ejecutar esta instrucción, inmediatamente aparecerá lo siguiente en la consola:
> summary(se.lm)
Call:
lm(formula = salario ~ escolaridad)
Residuals:
Min 1Q Median 3Q Max
-1.5637 -0.7350 0.1266 0.7158 1.3198
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.01445 0.87462 -0.017 0.987
escolaridad 0.72410 0.06958 10.406 4.96e-07 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.9387 on 11 degrees of freedom
Multiple R-squared: 0.9078, Adjusted R-squared: 0.8994
F-statistic: 108.3 on 1 and 11 DF, p-value: 4.958e-07
Usualmente el análisis de regresión se enfoca en el coeficiente que acompaña a la variable independiente y le resta importancia a los resultados expuestos sobre el intercepto. Dicho esto, podemos identificar los siguientes elementos en el resumen generado:

- La media de los residuos es igual a 0.1266, esto es un valor relativamente cercano a cero. Esto es algo que nos interesa pues es uno de los supuestos que debe cumplirse para que el Método de los Mínimos Cuadrados Ordinarios tenga validez.
- El valor del intercepto es
, esto quiere decir que una persona sin educación tiene un salario negativo y aunque esta situación carece se sentido, veremos en los demás resultados del resumen, que este valor tiene poca relevancia.
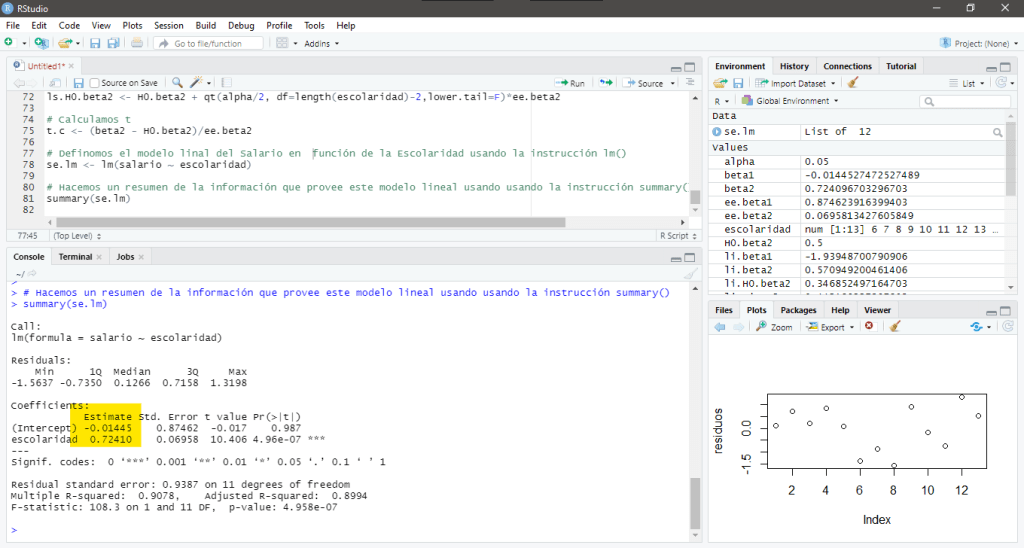
- El valor del coeficiente que acompaña a la variable
, esto quiere decir que cada año adicional de escolaridad, en promedio, produce aumentos en los salarios por hora de alrededor de 72 centavos de dólar.
- El modelo lineal está expresado de la siguiente forma:

- El error estándar correspondiente al nivel de estudios (escolaridad), indica que en promedio, las estimaciones variarán en 0.06958.

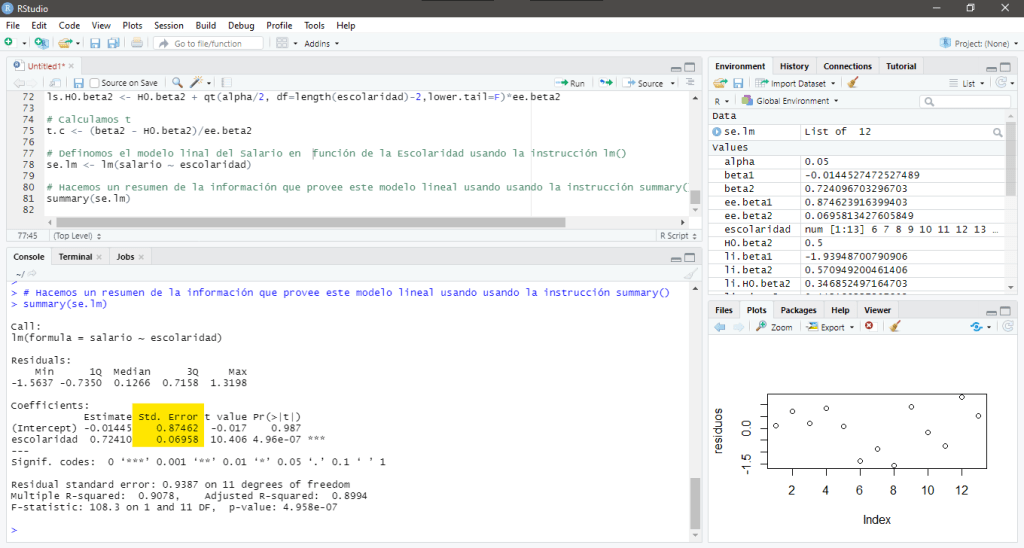
- El valor t para el estimador
- El valor t para el estimador
- El p-value para el estimador
- El p-value para el estimador
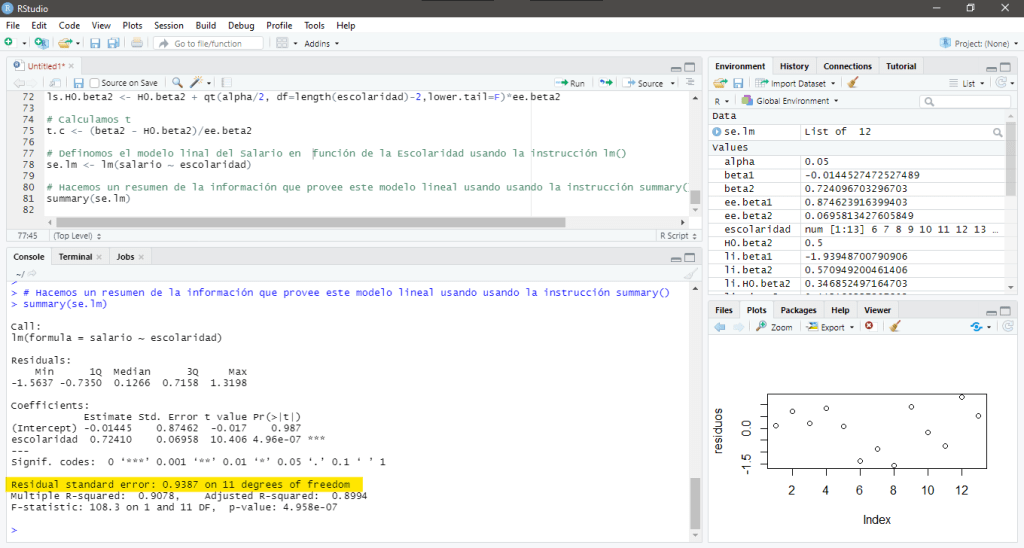
- El error estándar de los residuos es 0.9387, esto quiere decir que cualquier estimación que hagamos variará en 0.9387 centavos de dólar. Proporcionablemente, si comparamos esto con el promedio inicial -0.01445, tenemos que nuestra predicción se desviará en un 65.1875%.

- El coeficiente de determinación múltiple es igual a 0.9078 y el coeficiente de determinación ajustado es igual a 0.8994, recordemos que este último es corregido por la cantidad de variables y por eso es menor. En ambos casos, es relativamente alto, por lo que podemos concluir que los salarios están explicados en alrededor del 90% por el nivel de escolaridad.

- El valor F es igual a 108.3, es decir, está muy lejano de uno, por lo tanto la hipótesis nula se rechaza, y así, concluimos que el estimador
- El p-value para el estimador
Bibliografía
- Quick Guide: Interpreting Simple Linear Model Output in R. (2021). Feliperego.github.io. Retrieved 31 May 2021, from https://feliperego.github.io/blog/2015/10/23/Interpreting-Model-Output-In-R
- lm function – RDocumentation. (2021). Rdocumentation.org. Retrieved 31 May 2021, from https://www.rdocumentation.org/packages/stats/versions/3.6.2/topics/lm
- Conor Neilson (https://stats.stackexchange.com/users/130345/conor-neilson), What is the main difference between Multiple R squared and Adjusted R squared?, URL (version: 2016-10-20): https://stats.stackexchange.com/q/241298

 , los estimadores de MCO
, los estimadores de MCO 
 grados de libertad. Si el valor del verdadero
grados de libertad. Si el valor del verdadero ![P \left[ -t_{\alpha/2} \leq \dfrac{\hat{\beta}_i - \beta^*_i}{ee(\hat{\beta}_i)} \leq t_{\alpha/2} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+-t_%7B%5Calpha%2F2%7D+%5Cleq+%5Cdfrac%7B%5Chat%7B%5Cbeta%7D_i+-+%5Cbeta%5E%2A_i%7D%7Bee%28%5Chat%7B%5Cbeta%7D_i%29%7D+%5Cleq+t_%7B%5Calpha%2F2%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
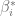 es el valor de
es el valor de 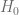 y
y  y
y  son los valores de
son los valores de 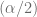 y
y 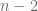 grados de libertad.
grados de libertad.![P \left[ \beta^*_i - t_{\alpha/2} ee(\hat{\beta}_i) \leq \hat{\beta}_i \leq \beta^*_i + t_{\alpha/2} ee(\hat{\beta}_i) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Cbeta%5E%2A_i+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cleq++%5Chat%7B%5Cbeta%7D_i++%5Cleq+%5Cbeta%5E%2A_i+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
 con probabilidad
con probabilidad 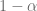 , dado
, dado  .
.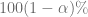 se conoce como la región de no rechazo (de la hipótesis nula
se conoce como la región de no rechazo (de la hipótesis nula 
![P \left[ \hat{\beta}_i - t_{\alpha/2} ee(\hat{\beta}_i) \leq \beta_i \leq \hat{\beta}_i + t_{\alpha/2} ee(\hat{\beta}_i) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Chat%7B%5Cbeta%7D_i+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cleq+%5Cbeta_i+%5Cleq+%5Chat%7B%5Cbeta%7D_i+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
![P \left[ \beta^*_i - t_{\alpha/2} ee(\hat{\beta}_i) \leq \hat{\beta}_i \leq \beta^*_i + t_{\alpha/2} ee(\hat{\beta}_i) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Cbeta%5E%2A_i+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cleq+%5Chat%7B%5Cbeta%7D_i++%5Cleq+%5Cbeta%5E%2A_i+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)

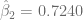 ,
,  y
y  . Si consideramos
. Si consideramos 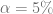 , entonces
, entonces  .
.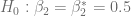 y la hipótesis alternativa
y la hipótesis alternativa  , calculamos los valores críticos en R usando la siguiente sintaxis:
, calculamos los valores críticos en R usando la siguiente sintaxis:

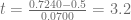 . Calculamos el valor de
. Calculamos el valor de 

 estimado se aleje del valor hipotético de
estimado se aleje del valor hipotético de  será cada vez mayor. Por consiguiente, un valor grande de
será cada vez mayor. Por consiguiente, un valor grande de 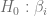 (con énfasis en
(con énfasis en  ) pues al rechazar esta hipótesis, podemos asegurar con cierto grado de confianza, que
) pues al rechazar esta hipótesis, podemos asegurar con cierto grado de confianza, que  y así, concluir que la variable que acompaña a
y así, concluir que la variable que acompaña a 
 y
y 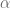 (
(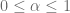 ) de modo que la probabilidad de que el intervalo aleatorio
) de modo que la probabilidad de que el intervalo aleatorio  contenga al verdadero
contenga al verdadero  , es decir,
, es decir,
 es el límite de confianza inferior y
es el límite de confianza inferior y 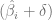 es el límite de confianza superior.
es el límite de confianza superior.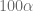 .
.
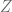 distribuida normalmente con media cero y varianza igual a uno, de la siguiente forma:
distribuida normalmente con media cero y varianza igual a uno, de la siguiente forma:
 .
.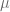 y varianza
y varianza  es cercana a 68%, que entre
es cercana a 68%, que entre  es alrededor de 95%, y que entre los límites
es alrededor de 95%, y que entre los límites  el área es cercana a 99.7%.
el área es cercana a 99.7%.


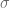 por
por  , tenemos que
, tenemos que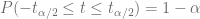
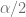 y
y 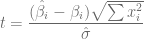 , podemos considerar el siguiente intervalo de confianza.
, podemos considerar el siguiente intervalo de confianza.![P \left[ -t_{\alpha/2} \leq \dfrac{\hat{\beta}_i - \beta_i}{ee(\hat{\beta}_i)} \leq t_{\alpha/2} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+-t_%7B%5Calpha%2F2%7D+%5Cleq+%5Cdfrac%7B%5Chat%7B%5Cbeta%7D_i+-+%5Cbeta_i%7D%7Bee%28%5Chat%7B%5Cbeta%7D_i%29%7D+%5Cleq+t_%7B%5Calpha%2F2%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
![P \left[ -t_{\alpha/2} \leq \dfrac{\hat{\beta}_2 - \beta_2}{ee(\hat{\beta}_2)} \leq t_{\alpha/2} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+-t_%7B%5Calpha%2F2%7D+%5Cleq+%5Cdfrac%7B%5Chat%7B%5Cbeta%7D_2+-+%5Cbeta_2%7D%7Bee%28%5Chat%7B%5Cbeta%7D_2%29%7D+%5Cleq+t_%7B%5Calpha%2F2%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
![P \left[ \hat{\beta}_2 - t_{\alpha/2} ee(\hat{\beta}_2) \leq \beta_2 \leq \hat{\beta}_2 + t_{\alpha/2} ee(\hat{\beta}_2) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Chat%7B%5Cbeta%7D_2+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_2%29+%5Cleq+%5Cbeta_2+%5Cleq+%5Chat%7B%5Cbeta%7D_2+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_2%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
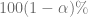 , que se escribe en forma más compacta como
, que se escribe en forma más compacta como
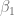
![P \left[ -t_{\alpha/2} \leq \dfrac{\hat{\beta}_1 - \beta_1}{ee(\hat{\beta}_1)} \leq t_{\alpha/2} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+-t_%7B%5Calpha%2F2%7D+%5Cleq+%5Cdfrac%7B%5Chat%7B%5Cbeta%7D_1+-+%5Cbeta_1%7D%7Bee%28%5Chat%7B%5Cbeta%7D_1%29%7D+%5Cleq+t_%7B%5Calpha%2F2%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
![P \left[ \hat{\beta}_1 - t_{\alpha/2} ee(\hat{\beta}_1) \leq \beta_1 \leq \hat{\beta}_1 + t_{\alpha/2} ee(\hat{\beta}_1) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Chat%7B%5Cbeta%7D_1+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_1%29+%5Cleq+%5Cbeta_1+%5Cleq+%5Chat%7B%5Cbeta%7D_1+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_1%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)


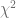 con
con 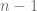 grados de libertad. Por lo tanto, con la distribución
grados de libertad. Por lo tanto, con la distribución 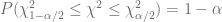
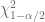 y
y  son dos valores de
son dos valores de  de las áreas de las colas de la distribución
de las áreas de las colas de la distribución 
 y operando algebraicamente en la inecuación, tenemos que
y operando algebraicamente en la inecuación, tenemos que![P \left[ (n-2) \dfrac{\hat{\sigma}^2}{\chi^2_{\alpha/2}} \leq \sigma^2 \leq (n-2) \dfrac{\hat{\sigma}^2}{\chi^2_{1-\alpha/2}} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%28n-2%29+%5Cdfrac%7B%5Chat%7B%5Csigma%7D%5E2%7D%7B%5Cchi%5E2_%7B%5Calpha%2F2%7D%7D+%5Cleq+%5Csigma%5E2+%5Cleq+%28n-2%29+%5Cdfrac%7B%5Chat%7B%5Csigma%7D%5E2%7D%7B%5Cchi%5E2_%7B1-%5Calpha%2F2%7D%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
 para
para 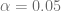 , podemos calcular los intervalos de confianza de ambos estimadores y además, el intervalo de confianza de la
, podemos calcular los intervalos de confianza de ambos estimadores y además, el intervalo de confianza de la 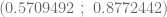

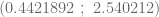


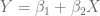

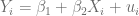

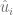 más pequeño posible, sin embargo, no podemos permitir que estos errores se anulen.
más pequeño posible, sin embargo, no podemos permitir que estos errores se anulen.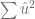







Debe estar conectado para enviar un comentario.