
Una vez que hemos calculado la función de regresión muestral como un modelo lineal a partir de un conjunto de datos, podemos notar en su gráfica que las observaciones no necesariamente caen sobre la línea que describe dicha función y aunque esta sería situación ideal (pues así podemos describir con precisión todo el conjunto de datos usando una función), esto no ocurre en la realidad.
También pudiera interesarte
La bondad de ajuste
Considerando el siguiente gráfico, si todas las observaciones cayeran en la línea de regresión, obtendríamos lo que se conoce como un ajuste perfecto, pero rara vez se presenta este caso. Por lo general los valores de 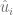

Aunque se tiene la esperanza de que los residuos alrededor de la línea de regresión sean lo más pequeños posibles, el coeficiente de determinación 
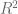
Antes de mostrar cómo calcular 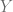
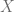
Si estos dos círculos no se intersectan, entonces la variación en


La intersección de los dos círculos (el área sombreada) indica la medida en la cual la variación en
Entre mayor sea el área de la intersección, mayor será la variación en

Si estos dos círculos se intersectan en su totalidad, es decir, son iguales, entonces la variación en


Para calcular 

Al elevar al cuadrado esta última ecuación en ambos lados y sumar sobre la muestra, obtenemos




Esa última igualdad se debe a que 

Las diversas sumas de cuadrados en esta ecuación se describen de la siguiente manera:
es la variación total de los valores reales de Y respecto de su media muestral, que puede denominarse la suma de cuadrados total (SCT).
es la variación de los valores de Y estimados alrededor de su media, que apropiadamente puede llamarse la suma de cuadrados debida a la regresión (es decir, debida a la variable explicativa), o explicada por ésta, o simplemente la suma de cuadrados explicada (SCE).
es la la variación residual o no explicada de los valores de Y alrededor de la línea de regresión, o sólo la suma de cuadrados de los residuos (SCR).
Por lo tanto, podemos reescribir la última ecuación de la siguiente manera:

Demostrando así, que la variación total en los valores
Dividiendo esta ecuación, entre la SCT a ambos lados tenemos que


Finalmente, definimos el coeficiente de determinación
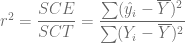
Podemos calcularlo en R usando la siguiente sintaxis:
r2 <- sum((Y.e - m.Y)^2)/sum((Y - m.Y)^2)También podemos definir el coeficiente de determinación

Podemos calcularlo en R usando la siguiente sintaxis:
r2 <- 1 - sum((Y - Y.e)^2)/sum((Y - m.Y)^2)Ejemplo
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
| Observación | Salario | Escolaridad |
| 1 | 4.4567 | 6 |
| 2 | 5.77 | 7 |
| 3 | 5.9787 | 8 |
| 4 | 7.3317 | 9 |
| 5 | 7.3182 | 10 |
| 6 | 6.5844 | 11 |
| 7 | 7.8182 | 12 |
| 8 | 7.8351 | 13 |
| 9 | 11.0223 | 14 |
| 10 | 10.6738 | 15 |
| 11 | 10.8361 | 16 |
| 12 | 13.615 | 17 |
| 13 | 13.531 | 18 |
Una vez que hemos calculado el modelo lineal que define este conjunto de datos, podemos calcular el coeficiente de determinación para ver qué tan relacionadas están las variables Salario y Escolaridad, para esto, usamos la siguiente sintaxis:
r2 <- sum((salario.e - m.salario)^2)/sum((salario - m.salario)^2)Al ejecutar estas instrucciones obtenemos coeficiente de determinación
En su pantalla debería aparecer:

En este caso, el valor del coeficiente de determinación sugiere que la variación en
