Estudiar el comportamiento de los residuos es de vital importancia para el análisis de regresión, pues varios de los supuestos del Modelo Clásico de Regresión Lineal (MCRL) hacen énfasis en los residuos, es por esto que se recurre a herramientas que nos permitan verificar si se cumplen estos supuestos y así, aumentar la confiabilidad sobre las conclusiones que se hagan a partir del modelo planteado.
También pudiera interesarte
Datos a considerar para los ejemplos
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
Observación
Salario
Escolaridad
1
4.4567
6
2
5.77
7
3
5.9787
8
4
7.3317
9
5
7.3182
10
6
6.5844
11
7
7.8182
12
8
7.8351
13
9
11.0223
14
10
10.6738
15
11
10.8361
16
12
13.615
17
13
13.531
18
Tabla 3.2
No-Autocorrelación
Sin consideramos dos valores de la variable independiente , digamos y con , la correlación entre dos y cualesquiera es cero. En pocas palabras, estas observaciones se muestrean de manera independiente. Es decir, se verifica que
o, si X no es estocástica,
Esta verificación se pude hacer de dos formas: Gráficamente o Estadísticamente.
Gráficamente
Diagrama de Dispersión
Haciendo diagrama de dispersión recurriendo a la instrucción plot(), entonces si previamente hemos definido el modelo lineal usando la instrucción lm() usamos la siguiente sintaxis:
plot(lm(Y~X)$residuals)
Este gráfico de dispersión se puede generar con mayor detalle usando la instrucción plot() sobre el modelo lineal, que genera cuatro gráficos pero en este caso nos interesarán sólo dos de ellos, el 1 y el 3:
plot(lm(Y~X),1)
plot(lm(Y~X),3)
Un indicador de no autocorrelación es que en el gráfico de dispersión no se presente ningún patrón lineal de comportamiento, en términos coloquiales: deben estar todos a lo loco. Dicho esto, los gráficos de dispersión, sirven principalmente como indicadores pero si no se tiene certeza sobre lo que se observa, lo mejor es llevar a cabo una prueba estadística.
Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos generar un diagrama de dispersión de los residuos y de la raíz cuadrada de los residuos estudentizados uno junto al otro combinando la instrucciones par() y plot(), para esto, usamos la siguiente sintaxis:
Al ejecutar esta instrucción obtenemos los gráficos que estamos buscando:
La línea roja es un ajuste local de los residuos (ponderada localmente) que suaviza los puntos del diagrama de dispersión para facilitad la detección patrones en los residuos. Lo que buscamos es que esta línea roja no describa un comportamiento lineal recta creciente ni decreciente.
En este ejemplo, la línea roja no es una línea recta creciente ni decreciente por lo que estos gráficos sugieren que los residuos no presentan autocorrelación. Hay que tomar en cuenta que los gráficos sirven meramente como indicadores, así que también se deben llevar a cabo pruebas estadísticas.
Estadísticamente
Prueba de Durbin-Watson
Para estudiar la autocorrelación de los residuos, es necesario estudiar la autocorrelación para cualesquiera dos y , esta tarea puede resultar tediosa, así que una de las alternativas es aplicar la Durbin-Watson test (Prueba de Durbin-Watson) que originalmente es usada para datos generados a través del tiempo (Series de Tiempo) para observar si existe una tendencia al comparar periodos previos. En este caso se estudia la relación entre los valores separados el uno del otro por un intervalo de tiempo igual a uno (cada elemento, con su anterior), esto es lo que se conoce como el rezago igual a 1.
Considerando una regresión auxiliar para los residuos expresada como una serie de tiempo usando el coeficiente de correlación , de la forma:
Se plantea la hipótesis nula de que usando el coeficiente de correlación y la hipótesis alternativa es , para probar esta hipótesis se define el siguiente estadístico de prueba:
Se denota con la letra (por Durbin-Watson). Entonces, considerando el coeficiente de correlación muestral de los residuos , el estadístico de prueba es aproximadamente , por lo tanto, si este estadístico de prueba es igual a 2, esto implica que indicando que no existe correlación (serial) entre los residuos.
Para llevar a cabo esta prueba en R, se carga a la librería lmtest y en ella recurrimos a la instrucción dbtest() usando la siguiente sintaxis:
library(lmtest)
dwtest(lm(Y~X))
Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos llevar a cabo la Prueba de Durbin-Watson, para esto, usamos la siguiente sintaxis:
library(lmtest)
dwtest(lm(salario~escolaridad))
Al ejecutar esta instrucción obtenemos los resultados de la prueba, donde nos interesará de forma particular que el p-value es igual a 0.1992, notando que este valor es mayor que 0.05, entonces no rechazamos la hipótesis nula y podemos asumir que los residuos no presentan autocorrelación.
También podemos finarnos en el estadístico de Durbin-Watson, que en este caso es igual a 1.738, que está cercano a 2. Entonces no rechazamos la hipótesis nula y podemos asumir que los residuos no presentan autocorrelación.
En su consola debería aparecer:
> dwtest(lm(salario~escolaridad))
Durbin-Watson test
data: lm(salario ~ escolaridad)
DW = 1.738, p-value = 0.1992
alternative hypothesis: true autocorrelation is greater than 0
Las pruebas expuestas en esta lección sirven para hacer algunas aseveraciones y su carácter didáctico es importante para entender el análisis de residuos, sin embargo, Jeffrey Wooldridge en su cuenta de twitter hace algunas observaciones que deben ser consideradas al hacer trabajos más especializados.
Tests that should be retired from empirical work:
Durbin-Watson statistic. Jarque-Bera test for normality. Breusch-Pagan test for heteroskedasticity. B-P test for random effects. Nonrobust Hausman tests.
Estudiar el comportamiento de los residuos es de vital importancia para el análisis de regresión, pues varios de los supuestos del Modelo Clásico de Regresión Lineal (MCRL) hacen énfasis en los residuos, es por esto que se recurre a herramientas que nos permitan verificar si se cumplen estos supuestos y así, aumentar la confiabilidad sobre las conclusiones que se hagan a partir del modelo planteado.
También pudiera interesarte
Datos a considerar para los ejemplos
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
Observación
Salario
Escolaridad
1
4.4567
6
2
5.77
7
3
5.9787
8
4
7.3317
9
5
7.3182
10
6
6.5844
11
7
7.8182
12
8
7.8351
13
9
11.0223
14
10
10.6738
15
11
10.8361
16
12
13.615
17
13
13.531
18
Tabla 3.2
Homocedasticidad
Para estudiar la homocedasticidad de los residuos o la homogeneidad de la varianza, se estudia qué tan constante es la varianza de los residuos, es decir, se estudia la heterocedasticidad de los residuos y se verifica que esta sea lo más pequeña posible. Para esto, es necesario estudentizar los residuos de la siguiente forma:
Posteriormente, comparamos los residuos estudentizados con los valores estimados de la variable dependiente y esto se pude hacer de dos formas: Gráficamente o Estadísticamente.
Gráficamente
Haciendo diagrama de dispersión recurriendo a la instrucción plot(), entonces si previamente hemos definido el modelo lineal usando la instrucción lm() usamos la siguiente sintaxis:
En un gráfico donde no haya heterocedasticidad (es decir, que indique homocedasticidad), es necesario que los puntos estén distribuidos de forma aleatoria y repartidos con equidad a través a lo largo del Eje Vertical, es decir, si se traza una recta horizontal en cero, estos no deberían estar acumulados ni por encima ni por debajo de esta recta.
Este gráfico de dispersión se puede generar con mayor detalle usando la instrucción plot() sobre el modelo lineal, que genera cuatro gráficos pero nos interesarán sólo dos de ellos, el 1 y el 3:
plot(lm(Y~X),1)
plot(lm(Y~X),3)
Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos generar un diagrama de dispersión de los residuos y de la raíz cuadrada de los residuos estudentizados uno junto al otro combinando la instrucciones par() y plot(), para esto, usamos la siguiente sintaxis:
Al ejecutar esta instrucción obtenemos los gráficos que estamos buscando:
La línea roja es un ajuste local de los residuos (ponderada localmente) que suaviza los puntos del diagrama de dispersión para facilitad la detección patrones en los residuos. La situación ideal es que esta línea roja sea una se asemeje a una recta horizonal centrada en cero.
En este ejemplo, la línea roja no es una recta horizonal centrada en cero pero estos parecieran estar al menos, distribuidos de forma aleatoria. Sin embargo, debido a la poca cantidad de datos, no podemos hacer una conclusión fehaciente.
Estadísticamente
Prueba de Breush-Pagan
La Breush-Pagan Test (Prueba de Breusch–Pagan), parte del hecho que la media de los residuos es igual a cero y si la varianza no depende de la variable independiente, se puede obtener una estimación de esta varianza a partir del promedio de los cuadrados de los residuos.
De esta forma, a partir del contrarrecíproco, se concluye que si esta estimación de la varianza no se puede obtener, entones la varianza está linealmente relacionada con la variable independiente. Para esto se define una regresión lineal auxiliar para el cuadrado de los residuos
Se plantea entonces como hipótesis nula que existe homocedasticidad y como hipótesis alternativa que existe heterocedasticidad. Es una prueba de chi-cuadrado: el estadístico de prueba se distribuye con grados de libertad. Si el estadístico de prueba tiene un p-value por debajo de un umbral apropiado, entonces se rechaza la hipótesis nula de homocedasticidad y se asume heterocedasticidad.
Para llevar a cabo esta prueba en R, se carga a la librería lmtest y en ella recurrimos a la instrucción bptest() usando la siguiente sintaxis:
library(lmtest)
bptest(lm(Y~X))
También se puede llevar a cabo esta prueba en R, cargando la librería car y en ella recurrimos a la instrucción ncvTest() usando la siguiente sintaxis:
library(car)
ncvTest(lm(Y~X))
Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos llevar a cabo la Prueba de Breusch–Pagan, para esto, usamos la siguiente sintaxis:
library(lmtest)
bptest(lm(salario~escolaridad))
Al ejecutar esta instrucción obtenemos los resultados de la prueba, donde nos interesará de forma particular que el p-value es igual a 0.3394, notando que este valor es mayor que 0.05, entonces no rechazamos la hipótesis nula y podemos asumir que existe homocedasticidad.
En su consola debería aparecer:
> library(lmtest)
> bptest(lm(salario~escolaridad))
studentized Breusch-Pagan test
data: lm(salario ~ escolaridad)
BP = 0.91274, df = 1, p-value = 0.3394
Las pruebas expuestas en esta lección sirven para hacer algunas aseveraciones y su carácter didáctico es importante para entender el análisis de residuos, sin embargo, Jeffrey Wooldridge en su cuenta de twitter hace algunas observaciones que deben ser consideradas al hacer trabajos más especializados.
Tests that should be retired from empirical work:
Durbin-Watson statistic. Jarque-Bera test for normality. Breusch-Pagan test for heteroskedasticity. B-P test for random effects. Nonrobust Hausman tests.
Estudiar el comportamiento de los residuos es de vital importancia para el análisis de regresión, pues varios de los supuestos del Modelo Clásico de Regresión Lineal (MCRL) hacen énfasis en los residuos, es por esto que se recurre a herramientas que nos permitan verificar si se cumplen estos supuestos y así, aumentar la confiabilidad sobre las conclusiones que se hagan a partir del modelo planteado.
También pudiera interesarte
Datos a considerar para los ejemplos
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
Observación
Salario
Escolaridad
1
4.4567
6
2
5.77
7
3
5.9787
8
4
7.3317
9
5
7.3182
10
6
6.5844
11
7
7.8182
12
8
7.8351
13
9
11.0223
14
10
10.6738
15
11
10.8361
16
12
13.615
17
13
13.531
18
Tabla 3.2
Media igual a cero
La media de los residuos (o perturbaciones) debe ser igual a cero. Para calcular en R la media de los residuos de nuestro modelo , recurrimos a la instrucción mean(), entonces si previamente hemos definido el modelo lineal usando la instrucción lm() usamos la siguiente sintaxis:
mean(Y-lm(Y~X)$fitted.values)
Donde, Y.e es la variable que almacena los valores estimados de . Sin embargo, recordando que si definimos el modelo lineal usando la instrucción lm(), podemos hacer un llamado a los residuos usando la sintaxis lm(Y~X)$residuals, de esta forma, podemos determinar la covarianza usando la siguiente sintaxis:
mean(lm(Y~X)$residuals)
También se pueden apreciar los residuos al observar un resumen del modelo lineal recurriendo la instrucción summary(), usando la siguiente sintaxis:
summary(lm(Y~X)$residuals)
Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos calcular la media de los residuos lm(salario~escolaridad)$residuals, para esto, usamos la siguiente sintaxis:
mean(lm(salario~escolaridad)$residuals)
Al ejecutar esta instrucción obtenemos la media de los residuos, que en este caso es igual a 8.515157e-18, notando que este valor es prácticamente cero, concluimos que la media de los residuos es igual a cero.
Estudiar el comportamiento de los residuos es de vital importancia para el análisis de regresión, pues varios de los supuestos del Modelo Clásico de Regresión Lineal (MCRL) hacen énfasis en los residuos, es por esto que se recurre a herramientas que nos permitan verificar si se cumplen estos supuestos y así, aumentar la confiabilidad sobre las conclusiones que se hagan a partir del modelo planteado.
También pudiera interesarte
Tabla de Contenidos
Los análisis que se exponen en esta lectura son los siguientes:
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
Observación
Salario
Escolaridad
1
4.4567
6
2
5.77
7
3
5.9787
8
4
7.3317
9
5
7.3182
10
6
6.5844
11
7
7.8182
12
8
7.8351
13
9
11.0223
14
10
10.6738
15
11
10.8361
16
12
13.615
17
13
13.531
18
Tabla 3.2
Residuos independientes
Una vez que hemos planteado un modelo lineal, es importante que los residuos alberguen toda esa información que no podemos explicar con la variable independiente, es por esta razón que uno de los supuestos del Modelo Clásico de Regresión Lineal propone que los residuos deben ser independientes de la variable independiente.
Considerando el caso en que la regresora es estocástica, los valores que toma la variable independiente pueden haber sido muestreados junto con la variable dependiente . En este caso se supone que la variable y el término de error son independientes , esto es,
.
Para calcular en R la covarianza de entre la variable independiente y los residuos de nuestro modelo , recurrimos a la instrucción cov() usando la siguiente sintaxis:
cov(X,Y-lm(Y~X)$fitted.values)
Donde, Y.e es la variable que almacena los valores estimados de . Sin embargo, recordando que si definimos el modelo lineal usando la instrucción lm(), podemos hacer un llamado a los residuos usando la sintaxis lm(Y~X)$residuals, de esta forma, podemos determinar la covarianza usando la siguiente sintaxis:
cov(X,lm(Y~X)$residuals)
Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos calcular la covarianza entre la variable independiente Escolaridad y los residuos lm(salario~escolaridad)$residuals, para esto, usamos la siguiente sintaxis:
Al ejecutar esta instrucción obtenemos la covarianza que buscamos, que en este caso es igual a 2.276825e-18, notando que este valor es prácticamente cero, concluimos que los residuos son independientes de la variable Escolaridad.
La media de los residuos (o perturbaciones) debe ser igual a cero. Para calcular en R la media de los residuos de nuestro modelo , recurrimos a la instrucción mean(), entonces si previamente hemos definido el modelo lineal usando la instrucción lm() usamos la siguiente sintaxis:
mean(Y-lm(Y~X)$fitted.values)
Donde, Y.e es la variable que almacena los valores estimados de . Sin embargo, recordando que si definimos el modelo lineal usando la instrucción lm(), podemos hacer un llamado a los residuos usando la sintaxis lm(Y~X)$residuals, de esta forma, podemos determinar la covarianza usando la siguiente sintaxis:
mean(lm(Y~X)$residuals)
También se pueden apreciar los residuos al observar un resumen del modelo lineal recurriendo la instrucción summary(), usando la siguiente sintaxis:
summary(lm(Y~X)$residuals)
Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos calcular la media de los residuos lm(salario~escolaridad)$residuals, para esto, usamos la siguiente sintaxis:
mean(lm(salario~escolaridad)$residuals)
Al ejecutar esta instrucción obtenemos la media de los residuos, que en este caso es igual a 8.515157e-18, notando que este valor es prácticamente cero, concluimos que la media de los residuos es igual a cero.
En su consola debería aparecer:
> mean(se.lm$residuals)
[1] 8.515157e-18
Anuncios
Homocedasticidad
Para estudiar la homocedasticidad de los residuos o la homogeneidad de la varianza, se estudia qué tan constante es la varianza de los residuos, es decir, se estudia la heterocedasticidad de los residuos y se verifica que esta sea lo más pequeña posible. Para esto, es necesario estudentizar de los residuos de la siguiente forma:
Posteriormente, comparamos los residuos estudentizados con los valores estimados de la variable dependiente y esto se pude hacer de dos formas: Gráficamente o Estadísticamente.
Gráficamente
Haciendo diagrama de dispersión recurriendo a la instrucción plot(), entonces si previamente hemos definido el modelo lineal usando la instrucción lm() usamos la siguiente sintaxis:
En un gráfico donde no haya heterocedasticidad (es decir, que indique homocedasticidad), es necesario que los puntos estén distribuidos de forma aleatoria y repartidos con equidad a través a lo largo del Eje Vertical, es decir, si se traza una recta horizontal en cero, estos no deberían estar acumulados ni por encima ni por debajo de esta recta.
Este gráfico de dispersión se puede generar con mayor detalle usando la instrucción plot() sobre el modelo lineal, que genera cuatro gráficos pero nos interesarán sólo dos de ellos, el 1 y el 3:
plot(lm(Y~X),1)
plot(lm(Y~X),3)
Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos generar un diagrama de dispersión de los residuos y de la raíz cuadrada de los residuos estudentizados uno junto al otro combinando la instrucciones par() y plot(), para esto, usamos la siguiente sintaxis:
Al ejecutar esta instrucción obtenemos los gráficos que estamos buscando:
La línea roja es un ajuste local de los residuos (ponderada localmente) que suaviza los puntos del diagrama de dispersión para facilitad la detección patrones en los residuos. La situación ideal es que esta línea roja sea una se asemeje a una recta horizonal centrada en cero.
En este ejemplo, la línea roja no es una recta horizonal centrada en cero pero estos parecieran estar al menos, distribuidos de forma aleatoria. Sin embargo, debido a la poca cantidad de datos, no podemos hacer una conclusión fehaciente.
Estadísticamente
Prueba de Breush-Pagan
La Breush-Pagan Test (Prueba de Breusch–Pagan), parte del hecho que la media de los residuos es igual a cero y si la varianza no depende de la variable independiente, se puede obtener una estimación de esta varianza a partir del promedio de los cuadrados de los residuos.
De esta forma, a partir del contrarrecíproco, se concluye que si esta estimación de la varianza no se puede obtener, entones la varianza está linealmente relacionada con la variable independiente. Para esto se define una regresión lineal auxiliar para el cuadrado de los residuos
Se plantea entonces como hipótesis nula que existe homocedasticidad y como hipótesis alternativa que existe heterocedasticidad. Es una prueba de chi-cuadrado: el estadístico de prueba se distribuye con grados de libertad. Si el estadístico de prueba tiene un p-value por debajo de un umbral apropiado, entonces se rechaza la hipótesis nula de homocedasticidad y se asume heterocedasticidad.
Para llevar a cabo esta prueba en R, se carga a la librería lmtest y en ella recurrimos a la instrucción bptest() usando la siguiente sintaxis:
library(lmtest)
bptest(lm(Y~X))
También se puede llevar a cabo esta prueba en R, cargando la librería car y en ella recurrimos a la instrucción ncvTest() usando la siguiente sintaxis:
library(car)
ncvTest(lm(Y~X))
Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos llevar a cabo la Prueba de Breusch–Pagan, para esto, usamos la siguiente sintaxis:
library(lmtest)
bptest(lm(salario~escolaridad))
Al ejecutar esta instrucción obtenemos los resultados de la prueba, donde nos interesará de forma particular que el p-value es igual a 0.3394, notando que este valor es mayor que 0.05, entonces no rechazamos la hipótesis nula y podemos asumir que existe homocedasticidad.
En su consola debería aparecer:
> library(lmtest)
> bptest(lm(salario~escolaridad))
studentized Breusch-Pagan test
data: lm(salario ~ escolaridad)
BP = 0.91274, df = 1, p-value = 0.3394
Anuncios
No-Autocorrelación
Sin consideramos dos valores de la variable independiente , digamos y con , la correlación entre dos y cualesquiera es cero. En pocas palabras, estas observaciones se muestrean de manera independiente. Es decir, se verifica que
o, si X no es estocástica,
Esta verificación se pude hacer de dos formas: Gráficamente o Estadísticamente.
Gráficamente
Diagrama de Dispersión
Haciendo diagrama de dispersión recurriendo a la instrucción plot(), entonces si previamente hemos definido el modelo lineal usando la instrucción lm() usamos la siguiente sintaxis:
plot(lm(Y~X)$residuals)
Este gráfico de dispersión se puede generar con mayor detalle usando la instrucción plot() sobre el modelo lineal, que genera cuatro gráficos pero en este caso nos interesarán sólo dos de ellos, el 1 y el 3:
plot(lm(Y~X),1)
plot(lm(Y~X),3)
Un indicador de no autocorrelación es que en el gráfico de dispersión no se presente ningún patrón lineal de comportamiento, en términos coloquiales: deben estar todos a lo loco. Dicho esto, los gráficos de dispersión, sirven principalmente como indicadores pero si no se tiene certeza sobre lo que se observa, lo mejor es llevar a cabo una prueba estadística.
Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos generar un diagrama de dispersión de los residuos y de la raíz cuadrada de los residuos estudentizados uno junto al otro combinando la instrucciones par() y plot(), para esto, usamos la siguiente sintaxis:
Al ejecutar esta instrucción obtenemos los gráficos que estamos buscando:
La línea roja es un ajuste local de los residuos (ponderada localmente) que suaviza los puntos del diagrama de dispersión para facilitad la detección patrones en los residuos. Lo que buscamos es que esta línea roja no describa un comportamiento lineal recta creciente ni decreciente.
En este ejemplo, la línea roja no es una línea recta creciente ni decreciente por lo que estos gráficos sugieren que los residuos no presentan autocorrelación. Hay que tomar en cuenta que los gráficos sirven meramente como indicadores, así que también se deben llevar a cabo pruebas estadísticas.
Estadísticamente
Prueba de Durbin-Watson
Para estudiar la autocorrelación de los residuos, es necesario estudiar la autocorrelación para cualesquiera dos y , esta tarea puede resultar tediosa, así que una de las alternativas es aplicar la Durbin-Watson test (Prueba de Durbin-Watson) que originalmente es usada para datos generados a través del tiempo (Series de Tiempo) para observar si existe una tendencia al comparar periodos previos. En este caso se estudia la relación entre los valores separados el uno del otro por un intervalo de tiempo igual a uno (cada elemento, con su anterior), esto es lo que se conoce como el rezago igual a 1.
Considerando una regresión auxiliar para los residuos expresada como una serie de tiempo usando el coeficiente de correlación , de la forma:
Se plantea la hipótesis nula de que usando el coeficiente de correlación y la hipótesis alternativa es , para probar esta hipótesis se define el siguiente estadístico de prueba:
Se denota con la letra (por Durbin-Watson). Entonces, considerando el coeficiente de correlación muestral de los residuos , el estadístico de prueba es aproximadamente , por lo tanto, si este estadístico de prueba es igual a 2, esto implica que indicando que no existe correlación (serial) entre los residuos.
Para llevar a cabo esta prueba en R, se carga a la librería lmtest y en ella recurrimos a la instrucción dbtest() usando la siguiente sintaxis:
library(lmtest)
dwtest(lm(Y~X))
Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos llevar a cabo la Prueba de Durbin-Watson, para esto, usamos la siguiente sintaxis:
library(lmtest)
dwtest(lm(salario~escolaridad))
Al ejecutar esta instrucción obtenemos los resultados de la prueba, donde nos interesará de forma particular que el p-value es igual a 0.1992, notando que este valor es mayor que 0.05, entonces no rechazamos la hipótesis nula y podemos asumir que los residuos no presentan autocorrelación.
También podemos finarnos en el estadístico de Durbin-Watson, que en este caso es igual a 1.738, que está cercano a 2. Entonces no rechazamos la hipótesis nula y podemos asumir que los residuos no presentan autocorrelación.
En su consola debería aparecer:
> dwtest(lm(salario~escolaridad))
Durbin-Watson test
data: lm(salario ~ escolaridad)
DW = 1.738, p-value = 0.1992
alternative hypothesis: true autocorrelation is greater than 0
Anuncios
Normalidad
El modelo clásico de regresión lineal normal supone que cada está normalmente distribuida si
Media:
Varianza:
Covarianza:
Estos supuestos se expresan en forma más compacta como
Donde el símbolo significa distribuido, denota distribución normal y los términos entre paréntesis representan los dos parámetros de la distribución normal: la media y la varianza, respectivamente.
Esta verificación se pude hacer de dos formas: Gráficamente o Estadísticamente.
Gráficamente
Histograma
Podemos graficar un histograma recurriendo a la instrucción hist() para hacer un histograma representando las frecuencias, entonces si previamente hemos definido el modelo lineal usando la instrucción lm() usamos la siguiente sintaxis:
hist(lm(Y~X)$residuals)
Aunque si queremos ver un histograma representando la densidad, incorporamos la opción prob = TRUE en la instrucción hist() y más aún, si queremos representar sobre nuestro histograma la línea de densidad, recurrimos a la instrucción line() en conjunto con la instrucción density() usando la siguiente sintaxis:
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos generar un histograma de los residuos usando la siguiente sintaxis:
Al ejecutar esta instrucción obtenemos el gráfico que estamos buscando:
El gráfico de barras que representa el histograma no demuestra de forma concreta una distribución normal y aunque la línea pareciera dibujar una especie de campana con una protuberancia en el lado izquierdo, no podemos hacer una conclusión fehaciente, así que también se deben llevar a cabo pruebas estadísticas.
Normal QQ-Plot
El QQ-Plot se traduce como el Diagrama de Cuantil-Cuantil y es un diagrama de dispersión que permite comparar distribución de probabilidades. Una gráfica Q-Q es una gráfica de dispersión creada al graficar dos conjuntos de cuantiles entre sí. Si ambos conjuntos de cuantiles provienen de la misma distribución, deberíamos ver los puntos formando una línea que es aproximadamente recta.
Es decir, al comparar la distribución de probabilidad normal con la distribución de probabilidad de los residuos de nuestro modelo lineal, si estos forman una línea recta, este es un indicador de que los residuos están distribuidos de forma normal.
Este gráfico se puede generar con usando la instrucción plot() sobre el modelo lineal, que genera cuatro gráficos pero en este caso nos interesará sólo uno de ellos, el 2:
plot(lm(Y~X),2)
Ejemplo
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos generar un histograma de los residuos usando la siguiente sintaxis:
plot(lm(salario~escolaridad),2)
Al ejecutar esta instrucción obtenemos el gráfico que estamos buscando:
Aunque no de forma precisa, podemos notar que el diagrama de dispersión pareciera ajustarse a la recta indentidad, representada con una línea punteada, por lo que este gráfico sugiere que sí hay una distribución normal de los residuos. Sin embargo, no podemos hacer una conclusión fehaciente, así que también se deben llevar a cabo pruebas estadísticas.
Estadísticamente
Jarque–Bera test
La Prueba de Jarque-Bera partiendo del hecho de que una distribución normal tiene coeficiente de asimetría igual a 0 y Curtosis igual a 3. Estos dos elementos se miden a partir de los residuos de nuestro modelo lineal usando la siguientes formulas, respectivamente:
y
Definiendo así el coeficiente de asimetría () y la curtosis (), se define el estadístico de Jarque-Bera de la siguiente forma:
Si el valor del estadístico es igual a cero, este es un indicador de que la distribución de los residuos es normal. Más aún, El estadístico de Jarque-Bera se distribuye asintóticamente como una distribución chi cuadrado con dos grados de libertad y puede usarse para probar la hipótesis nula de que los datos pertenecen a una distribución normal. La hipótesis nula es una hipótesis conjunta de que la asimetría y el exceso de curtosis son nulos (asimetría = 0 y curtosis = 3)
Para llevar a cabo esta prueba en R, se carga a la librería tseries y en ella recurrimos a la instrucción jarque.bera.test() usando la siguiente sintaxis:
Una vez que hemos calculado el modelo lineal que define este conjunto de datos usando la instrucción lm(), podemos llevar a cabo la Prueba de Jarque-Bera, para esto, usamos la siguiente sintaxis:
Al ejecutar esta instrucción obtenemos los resultados de la prueba, donde nos interesará de forma particular que el p-value es igual a 0.6608, notando que este valor es mayor que 0.05, entonces no rechazamos la hipótesis nula y podemos asumir que el coeficiente de asimetría es igual a cero y que la curtosis es igual tres, por lo que asumimos que los residuos tienen una distribución normal.
En su consola debería aparecer:
> library(tseries)
> jarque.bera.test(se.lm$residuals)
Jarque Bera Test
data: se.lm$residuals
X-squared = 0.8287, df = 2, p-value = 0.6608
Las pruebas expuestas en esta lección sirven para hacer algunas aseveraciones y su carácter didáctico es importante para entender el análisis de residuos, sin embargo, Jeffrey Wooldridge en su cuenta de twitter hace algunas observaciones que deben ser consideradas al hacer trabajos más especializados.
Tests that should be retired from empirical work:
Durbin-Watson statistic. Jarque-Bera test for normality. Breusch-Pagan test for heteroskedasticity. B-P test for random effects. Nonrobust Hausman tests.


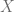

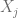
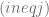

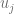
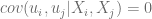



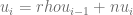

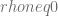



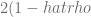

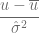
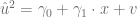
 con
con 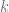 grados de libertad. Si el estadístico de prueba tiene un p-value por debajo de un umbral apropiado, entonces se rechaza la hipótesis nula de homocedasticidad y se asume heterocedasticidad.
grados de libertad. Si el estadístico de prueba tiene un p-value por debajo de un umbral apropiado, entonces se rechaza la hipótesis nula de homocedasticidad y se asume heterocedasticidad. , recurrimos a la instrucción mean(), entonces si previamente hemos definido el modelo lineal usando la instrucción lm() usamos la siguiente sintaxis:
, recurrimos a la instrucción mean(), entonces si previamente hemos definido el modelo lineal usando la instrucción lm() usamos la siguiente sintaxis: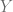 . Sin embargo, recordando que si definimos el modelo lineal usando la instrucción lm(), podemos hacer un llamado a los residuos usando la sintaxis lm(Y~X)$residuals, de esta forma, podemos determinar la covarianza usando la siguiente sintaxis:
. Sin embargo, recordando que si definimos el modelo lineal usando la instrucción lm(), podemos hacer un llamado a los residuos usando la sintaxis lm(Y~X)$residuals, de esta forma, podemos determinar la covarianza usando la siguiente sintaxis: .
. con
con 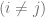 , la correlación entre dos
, la correlación entre dos 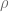 , de la forma:
, de la forma: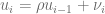
 y la hipótesis alternativa es
y la hipótesis alternativa es  , para probar esta hipótesis se define el siguiente estadístico de prueba:
, para probar esta hipótesis se define el siguiente estadístico de prueba:
 , el estadístico de prueba
, el estadístico de prueba  , por lo tanto, si este estadístico de prueba es igual a 2, esto implica que
, por lo tanto, si este estadístico de prueba es igual a 2, esto implica que  indicando que no existe correlación (serial) entre los residuos.
indicando que no existe correlación (serial) entre los residuos.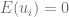



 significa distribuido,
significa distribuido,  denota distribución normal y los términos entre paréntesis representan los dos parámetros de la distribución normal: la media y la varianza, respectivamente.
denota distribución normal y los términos entre paréntesis representan los dos parámetros de la distribución normal: la media y la varianza, respectivamente.

 y
y 
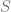 ) y la curtosis (
) y la curtosis (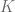 ), se define el estadístico de Jarque-Bera de la siguiente forma:
), se define el estadístico de Jarque-Bera de la siguiente forma: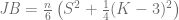

Debe estar conectado para enviar un comentario.