
Una vez que hemos aprendido a calcular los intervalos de confianza podemos definir un entorno donde pudiera vivir nuestro parámetro poblacional, sin embargo, es necesario definir un elemento que nos permita usar este entorno para determinar si el planteamiento de nuestra investigación, se ajusta a la estimación que hemos hecho.
La idea básica de las pruebas de significancia es la de definir un estadístico de prueba y su distribución muestral según la hipótesis nula. La decisión de rechazar o no rechazar la hipótesis nula se toma con base en el valor del estadístico de prueba obtenido con los datos disponibles.
También pudiera interesarte
Prueba de significancia de los coeficientes de regresión: la prueba t
Con el supuesto de normalidad de 
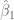


Sigue la distribución 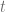


Y como este estadístico de prueba sigue una distribución
![P \left[ -t_{\alpha/2} \leq \dfrac{\hat{\beta}_i - \beta^*_i}{ee(\hat{\beta}_i)} \leq t_{\alpha/2} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+-t_%7B%5Calpha%2F2%7D+%5Cleq+%5Cdfrac%7B%5Chat%7B%5Cbeta%7D_i+-+%5Cbeta%5E%2A_i%7D%7Bee%28%5Chat%7B%5Cbeta%7D_i%29%7D+%5Cleq+t_%7B%5Calpha%2F2%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
donde 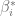
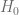


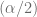
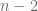
Reescribiendo la inecuación involucrada, tenemos que
![P \left[ \beta^*_i - t_{\alpha/2} ee(\hat{\beta}_i) \leq \hat{\beta}_i \leq \beta^*_i + t_{\alpha/2} ee(\hat{\beta}_i) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Cbeta%5E%2A_i+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cleq++%5Chat%7B%5Cbeta%7D_i++%5Cleq+%5Cbeta%5E%2A_i+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
obteniendo así, el intervalo en el cual se encontrará 
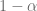

Calculamos los valores críticos en R usando la siguiente sintaxis:
li.H0.betai <- betai - qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.betai
ls.H0.betai <- betai + qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.betaiEn el lenguaje de pruebas de hipótesis, este intervalo de confianza a 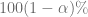

Los límites de confianza dados por los puntos extremos del intervalo de confianza se llaman también valores críticos.
Ahora se aprecia la estrecha conexión entre los enfoques de intervalo de confianza y prueba de significancia para realizar pruebas de hipótesis, pues al compararlos, tenemos que:
En el enfoque de intervalo de confianza se trata de establecer un rango o intervalo que tenga una probabilidad determinada de contener al verdadero aunque desconocido
![P \left[ \hat{\beta}_i - t_{\alpha/2} ee(\hat{\beta}_i) \leq \beta_i \leq \hat{\beta}_i + t_{\alpha/2} ee(\hat{\beta}_i) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Chat%7B%5Cbeta%7D_i+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cleq+%5Cbeta_i+%5Cleq+%5Chat%7B%5Cbeta%7D_i+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
En el enfoque de prueba de significancia se somete a hipótesis algún valor de
![P \left[ \beta^*_i - t_{\alpha/2} ee(\hat{\beta}_i) \leq \hat{\beta}_i \leq \beta^*_i + t_{\alpha/2} ee(\hat{\beta}_i) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Cbeta%5E%2A_i+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cleq+%5Chat%7B%5Cbeta%7D_i++%5Cleq+%5Cbeta%5E%2A_i+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
Sin embargo, en la práctica, no hay necesidad de estimar este intervalo explícitamente. Se calcula el valor de
t.c <- (betai - H0.betai)/ee.betai
Ejemplo
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
| Observación | Salario | Escolaridad |
| 1 | 4.4567 | 6 |
| 2 | 5.77 | 7 |
| 3 | 5.9787 | 8 |
| 4 | 7.3317 | 9 |
| 5 | 7.3182 | 10 |
| 6 | 6.5844 | 11 |
| 7 | 7.8182 | 12 |
| 8 | 7.8351 | 13 |
| 9 | 11.0223 | 14 |
| 10 | 10.6738 | 15 |
| 11 | 10.8361 | 16 |
| 12 | 13.615 | 17 |
| 13 | 13.531 | 18 |
Sabiendo que 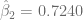


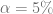

Considerando la hipótesis nula 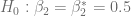

H0.beta2 <- 0.5
li.H0.beta2 <- H0.beta2 - qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.beta2
ls.H0.beta2 <- H0.beta2 + qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.beta2Una vez ejecutadas estas instrucciones, obtenemos que

De forma gráfica, podemos expresar esta probabilidad así

Notamos entonces, que el valor
Veamos ahora, qué es lo que ocurre con el valor que hemos calculado de 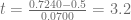
H0.beta2 <- 0.5
t.c <- (beta2 - H0.beta2)/ee.beta2En el siguiente gráfico, vemos con claridad que el valor se encuentra en la región crítica y la conclusión se mantiene; es decir, rechazamos

En su pantalla debería aparecer:

Notas:
Observe que si el 

En la práctica, se plantea la hipótesis nula 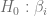



 y
y 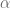 (
(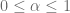 ) de modo que la probabilidad de que el intervalo aleatorio
) de modo que la probabilidad de que el intervalo aleatorio  contenga al verdadero
contenga al verdadero  , es decir,
, es decir,
 es el límite de confianza inferior y
es el límite de confianza inferior y 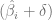 es el límite de confianza superior.
es el límite de confianza superior.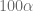 .
.
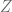 distribuida normalmente con media cero y varianza igual a uno, de la siguiente forma:
distribuida normalmente con media cero y varianza igual a uno, de la siguiente forma:
 .
.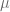 y varianza
y varianza  es cercana a 68%, que entre
es cercana a 68%, que entre  es alrededor de 95%, y que entre los límites
es alrededor de 95%, y que entre los límites  el área es cercana a 99.7%.
el área es cercana a 99.7%.


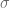 por
por  , tenemos que
, tenemos que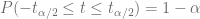
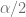 y
y 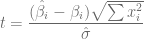 , podemos considerar el siguiente intervalo de confianza.
, podemos considerar el siguiente intervalo de confianza.![P \left[ -t_{\alpha/2} \leq \dfrac{\hat{\beta}_i - \beta_i}{ee(\hat{\beta}_i)} \leq t_{\alpha/2} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+-t_%7B%5Calpha%2F2%7D+%5Cleq+%5Cdfrac%7B%5Chat%7B%5Cbeta%7D_i+-+%5Cbeta_i%7D%7Bee%28%5Chat%7B%5Cbeta%7D_i%29%7D+%5Cleq+t_%7B%5Calpha%2F2%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
![P \left[ -t_{\alpha/2} \leq \dfrac{\hat{\beta}_2 - \beta_2}{ee(\hat{\beta}_2)} \leq t_{\alpha/2} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+-t_%7B%5Calpha%2F2%7D+%5Cleq+%5Cdfrac%7B%5Chat%7B%5Cbeta%7D_2+-+%5Cbeta_2%7D%7Bee%28%5Chat%7B%5Cbeta%7D_2%29%7D+%5Cleq+t_%7B%5Calpha%2F2%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
![P \left[ \hat{\beta}_2 - t_{\alpha/2} ee(\hat{\beta}_2) \leq \beta_2 \leq \hat{\beta}_2 + t_{\alpha/2} ee(\hat{\beta}_2) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Chat%7B%5Cbeta%7D_2+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_2%29+%5Cleq+%5Cbeta_2+%5Cleq+%5Chat%7B%5Cbeta%7D_2+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_2%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
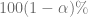 , que se escribe en forma más compacta como
, que se escribe en forma más compacta como
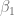
![P \left[ -t_{\alpha/2} \leq \dfrac{\hat{\beta}_1 - \beta_1}{ee(\hat{\beta}_1)} \leq t_{\alpha/2} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+-t_%7B%5Calpha%2F2%7D+%5Cleq+%5Cdfrac%7B%5Chat%7B%5Cbeta%7D_1+-+%5Cbeta_1%7D%7Bee%28%5Chat%7B%5Cbeta%7D_1%29%7D+%5Cleq+t_%7B%5Calpha%2F2%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
![P \left[ \hat{\beta}_1 - t_{\alpha/2} ee(\hat{\beta}_1) \leq \beta_1 \leq \hat{\beta}_1 + t_{\alpha/2} ee(\hat{\beta}_1) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Chat%7B%5Cbeta%7D_1+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_1%29+%5Cleq+%5Cbeta_1+%5Cleq+%5Chat%7B%5Cbeta%7D_1+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_1%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)


 con
con 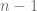 grados de libertad. Por lo tanto, con la distribución
grados de libertad. Por lo tanto, con la distribución 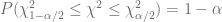
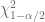 y
y  son dos valores de
son dos valores de  de las áreas de las colas de la distribución
de las áreas de las colas de la distribución 
 y operando algebraicamente en la inecuación, tenemos que
y operando algebraicamente en la inecuación, tenemos que![P \left[ (n-2) \dfrac{\hat{\sigma}^2}{\chi^2_{\alpha/2}} \leq \sigma^2 \leq (n-2) \dfrac{\hat{\sigma}^2}{\chi^2_{1-\alpha/2}} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%28n-2%29+%5Cdfrac%7B%5Chat%7B%5Csigma%7D%5E2%7D%7B%5Cchi%5E2_%7B%5Calpha%2F2%7D%7D+%5Cleq+%5Csigma%5E2+%5Cleq+%28n-2%29+%5Cdfrac%7B%5Chat%7B%5Csigma%7D%5E2%7D%7B%5Cchi%5E2_%7B1-%5Calpha%2F2%7D%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
 para
para 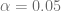 , podemos calcular los intervalos de confianza de ambos estimadores y además, el intervalo de confianza de la
, podemos calcular los intervalos de confianza de ambos estimadores y además, el intervalo de confianza de la 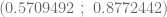

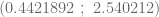


 ,
,  ,
,  y
y 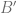 .
.
 , definimos un nuevo valor que está íntimamente relacionado con dicha fórmula pero que conceptualmente son diferentes. Entonces, partiendo del hecho que,
, definimos un nuevo valor que está íntimamente relacionado con dicha fórmula pero que conceptualmente son diferentes. Entonces, partiendo del hecho que,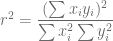
 , conocido como el Coeficiente de Correlación Muestral, que mide el grado de asociación lineal entre dos variables y se calcula de la siguiente forma:
, conocido como el Coeficiente de Correlación Muestral, que mide el grado de asociación lineal entre dos variables y se calcula de la siguiente forma:
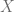 y
y 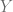 (
( ) es el mismo que entre
) es el mismo que entre  ).
).










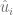 pueden ser positivos o negativos, gráficamente, podemos decir que algunas observaciones estarán por encima de la línea de regresión y otras por debajo.
pueden ser positivos o negativos, gráficamente, podemos decir que algunas observaciones estarán por encima de la línea de regresión y otras por debajo.
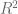 (regresión múltiple) es una medida comprendida que dice que tan bien se ajusta la línea de regresión muestral a los datos.
(regresión múltiple) es una medida comprendida que dice que tan bien se ajusta la línea de regresión muestral a los datos.




 , que expresado en forma de desviación, es decir, como la diferencia de cada observación con la media,
, que expresado en forma de desviación, es decir, como la diferencia de cada observación con la media,




 y
y  .
.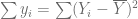 es la variación total de los valores reales de Y respecto de su media muestral, que puede denominarse la suma de cuadrados total (SCT).
es la variación total de los valores reales de Y respecto de su media muestral, que puede denominarse la suma de cuadrados total (SCT). es la variación de los valores de Y estimados alrededor de su media, que apropiadamente puede llamarse la suma de cuadrados debida a la regresión (es decir, debida a la variable explicativa), o explicada por ésta, o simplemente la suma de cuadrados explicada (SCE).
es la variación de los valores de Y estimados alrededor de su media, que apropiadamente puede llamarse la suma de cuadrados debida a la regresión (es decir, debida a la variable explicativa), o explicada por ésta, o simplemente la suma de cuadrados explicada (SCE). es la la variación residual o no explicada de los valores de Y alrededor de la línea de regresión, o sólo la suma de cuadrados de los residuos (SCR).
es la la variación residual o no explicada de los valores de Y alrededor de la línea de regresión, o sólo la suma de cuadrados de los residuos (SCR).


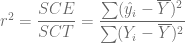



Debe estar conectado para enviar un comentario.