
Una vez que se determina el Producto Interno Bruto de un país, ¿qué cantidad de este dinero le corresponde a cada ciudadano? Independientemente de cómo esté distribuida la riqueza entre los habitantes de un país, por distintas razones (justas o no), esta distribución no es equitativa, de ahí radica la importancia de presentar un modelo matemático que permita describir esta distribución.
También pudiera interesarte
La Curva de Lorenz
La Curva de Lorenz es una función que permite describir la distribución de la riqueza de en un país y también es conocida como la Línea de Desigualdad Perfecta. Usualmente esta se denota como 
- Esta función corresponde a valores desde el 0% de la población acumulada hasta el 100% de la población acumulada, es decir,
.
- Esta función corresponde a valores desde el 0% de ingresos acumulados hasta el 100% de los ingresos acumulados, es decir,
.
- El 0% de los ingresos es repartido entre el 0% de la población, es decir,
.
- El 100% de los ingresos es repartido entre el 110% de la población, es decir,
.
- La distribución de los ingresos nunca es equitativa, es decir,
para todo
en su dominio.
Este último punto se debe a que la distribución equitativa de los ingresos se representa con la función identidad, es decir, con la función 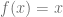

Veamos en los siguientes ejemplos algunas Curva de Lorenz y la distribución de los ingresos que estas describen.
Ejemplos
Ejemplo 1
Considere la función 
- Si evaluamos esta función en
, tenemos que
esto implica que el 20% de la población percibe el 14.66% de los ingresos.
- Si evaluamos esta función en
, tenemos que
esto implica que el 40% de la población percibe el 32% de los ingresos.
- Si evaluamos esta función en
, tenemos que
esto implica que el 75% de la población percibe el 68.75% de los ingresos.
La función

Ejemplo 2
Considere la función 
- Si evaluamos esta función en
, tenemos que
esto implica que el 15% de la población percibe el 1.3% de los ingresos.
- Si evaluamos esta función en
, tenemos que
esto implica que el 50% de la población percibe el 15.88% de los ingresos.
- Si evaluamos esta función en
, tenemos que
esto implica que el 80% de la población percibe el 49.30% de los ingresos.
La función

Si te ha parecido útil la información que hemos presentado en totumat y quieres ayudar a mantener este sitio en línea puedes mirar nuestros anuncios publicitarios o donar dinero a través de PayPal.
El Coeficiente de Gini
Es notable que en algunos casos la Curva de Lorenz está más cercana a la recta identidad pero en otros, está más lejana, lo que pudiera indicar que tan desigual es la distribución de los ingresos. Observando esta situación, vale la pena preguntarse: ¿habrá una forma cuantificar esta diferencia? La respuesta es sí.
El Coeficiente de Gini mide la separación de la Curva de Lorenz respecto a la Línea de Igualdad Perfecta para determinar el grado de desigualdad que existe en la distribución de los ingreso, para llevar a cabo esta medición, consideramos las áreas A (roja) y B (azul) expresadas en el siguiente gráfico:

- El área A es el área entre la Línea de Igualdad Perfecta y la Curva de Lorenz.
- El área B es el área bajo la Curva de Lorenz.
El Coeficiente de Gini se determina calculando el cociente entre la área A y la suma de las áreas A+B, es decir,

Pero podemos notar inmediatamente que la suma de las áreas 

Obtenemos una nueva expresión para calcular el Coeficiente de Gini, que será multiplicar el área A por 2:

Esta fórmula para calcular el Coeficiente de Gini nos indica que tan amplia es el área A y en consecuencia, qué tan alejada está la distribución de los ingresos de una distribución equitativa perfecta. Es por esto que al calcular este coeficiente, debemos tomar en cuenta que:
- Si el Coeficiente de Gini está cercano a cero, esto quiere decir que la Curva de Lorenz está cerca de la Línea de Igualdad Perfecta y en consecuencia, la distribución de los ingresos tiende a ser equitativa.
- Si el Coeficiente de Gini está cercano a uno, esto quiere decir que la Curva de Lorenz está alejada de la Línea de Igualdad Perfecta y en consecuencia, la distribución de los ingresos tiende a ser desigual.
En los siguientes ejemplos, veremos usaremos la fórmula para calcular el Coeficiente de Gini y veremos su interpretación.
Ejemplos
Ejemplo 3
Considerando la Curva de Lorenz
Representamos gráficamente la función

Calculamos el área A, identificada con rojo:



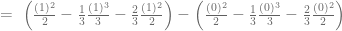
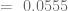
Por lo tanto, el Coeficiente de Gini es:

Al estar este valor cercano a cero, concluimos que la distribución de los ingresos tiende a ser equitativa.
- Considerando la Curva de Lorenz
, calcule el Coeficiente de Gini e interprete su resultado.
Representamos gráficamente la función

Calculamos el área A, identificada con rojo:




Por lo tanto, el Coeficiente de Gini es:

Al estar este valor está más cercano a uno, que a cero, concluimos que la distribución de los ingresos tiende a ser desigual.

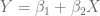

 y el parámetro
y el parámetro  , debido a que estos dos elementos permanecen inalterados. Sin embargo, no es lineal respecto al parámetro
, debido a que estos dos elementos permanecen inalterados. Sin embargo, no es lineal respecto al parámetro 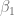 pues este está multiplicado por sí mismo, tampoco es lineal respecto a la variable
pues este está multiplicado por sí mismo, tampoco es lineal respecto a la variable 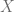 pues esta está alterada por la función logaritmo neperiano.
pues esta está alterada por la función logaritmo neperiano.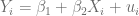

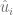 más pequeño posible, sin embargo, no podemos permitir que estos errores se anulen.
más pequeño posible, sin embargo, no podemos permitir que estos errores se anulen.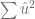
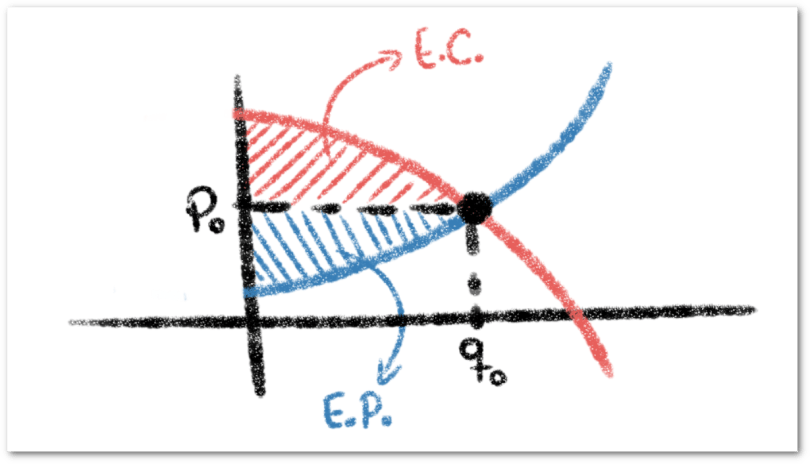
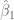 y
y  se calculan de la siguiente forma:
se calculan de la siguiente forma:





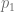 Perolitos (Ps.), los consumidores estarán dispuestos a comprar
Perolitos (Ps.), los consumidores estarán dispuestos a comprar 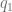 unidades de dicho artículo.
unidades de dicho artículo.
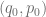 , podemos notar que aquellos consumidores que están dispuestos a comprar
, podemos notar que aquellos consumidores que están dispuestos a comprar 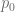 Ps.
Ps.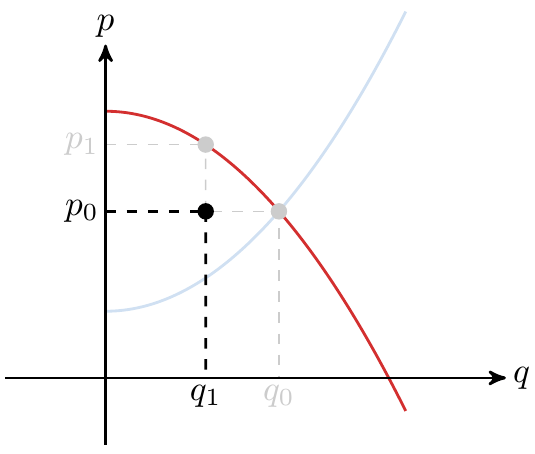
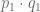 Ps. (precio por unidad multiplicado por la cantidad adquirida), una vez que se ha fijado el precio de equilibrio, gastará
Ps. (precio por unidad multiplicado por la cantidad adquirida), una vez que se ha fijado el precio de equilibrio, gastará  Ps. Esto genera un beneficio para los consumidores, y a partir de este hecho surge la siguiente pregunta: ¿es posible cuantificar este beneficio?
Ps. Esto genera un beneficio para los consumidores, y a partir de este hecho surge la siguiente pregunta: ¿es posible cuantificar este beneficio?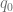 , fijada por el punto de equilibrio. El gasto que pagarían originalmente, está representado por el área que está debajo de la función de demanda de la siguiente forma,
, fijada por el punto de equilibrio. El gasto que pagarían originalmente, está representado por el área que está debajo de la función de demanda de la siguiente forma,


 , determinamos el excedente de los consumidores calculando la siguiente integral definida:
, determinamos el excedente de los consumidores calculando la siguiente integral definida:





 , determinamos el excedente de los productores calculando la siguiente integral definida:
, determinamos el excedente de los productores calculando la siguiente integral definida:
 y la ecuación de oferta
y la ecuación de oferta  , calcule el punto de equilibrio del mercado; posteriormente calcule el excedente de los consumidores y el excedente de los fabricantes.
, calcule el punto de equilibrio del mercado; posteriormente calcule el excedente de los consumidores y el excedente de los fabricantes.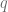 .
.


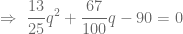

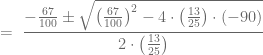
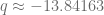 ó
ó 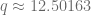 , pero al ser
, pero al ser 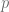 . Sustituyamos en este caso el valor de
. Sustituyamos en este caso el valor de 
 . Grafiquemos ahora el punto de equilibrio del mercado e identifiquemos las áreas que definen los excedentes.
. Grafiquemos ahora el punto de equilibrio del mercado e identifiquemos las áreas que definen los excedentes.
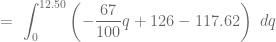








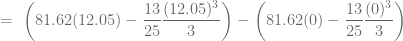
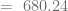
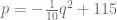 y la ecuación de oferta
y la ecuación de oferta  , calcule el punto de equilibrio del mercado; posteriormente calcule el excedente de los consumidores y el excedente de los fabricantes.
, calcule el punto de equilibrio del mercado; posteriormente calcule el excedente de los consumidores y el excedente de los fabricantes.
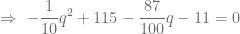

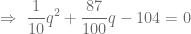


 ó
ó  , pero al ser
, pero al ser 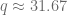 en la ecuación de oferta.
en la ecuación de oferta.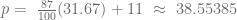
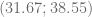 . Grafiquemos ahora el punto de equilibrio del mercado e identifiquemos las áreas que definen los excedentes.
. Grafiquemos ahora el punto de equilibrio del mercado e identifiquemos las áreas que definen los excedentes.
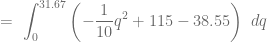

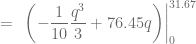


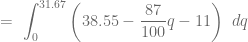

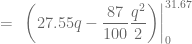
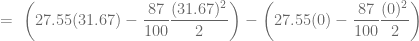
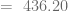

 observaciones
observaciones 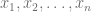 , la media se calcula usando la siguiente fórmula:
, la media se calcula usando la siguiente fórmula: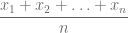
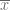 , la varianza se calcula usando la siguiente fórmula:
, la varianza se calcula usando la siguiente fórmula: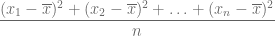












Debe estar conectado para enviar un comentario.