
Hemos visto que el coeficiente de determinación nos permite determinar en qué medida dos variables están relacionadas, pero siempre resulta de interés preguntarse si es posible determinar la forma en que estas dos variables están relacionadas, particularmente, en qué medida están correlacionadas.
También pudiera interesarte
Coeficiente de Correlación Muestral
Considerando una de las fórmulas para calcular el coeficiente de determinación 
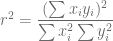
Definimos un nuevo valor 

Podemos calcularlo en R usando la siguiente sintaxis:
r <- sum((X-m.X)*(Y-m.Y))/sqrt(sum((X - m.X)^2)*sum((Y - m.Y)^2))Es importante destacar que:
Aunque el coeficiente de correlación r es una medida de asociación lineal entre dos variables, este no implica necesariamente alguna relación causa-efecto.
Una ventaja en el cálculo de este coeficiente, es que es simétrico por la forma en que está definido, es decir, el coeficiente de correlación entre 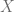


Interpretación Gráfica del Coeficiente de Correlación Muestral
A diferencia de
Si valor del coeficiente de correlación

Si valor del coeficiente de correlación

Si valor del coeficiente de correlación

Si valor del coeficiente de correlación

Si valor del coeficiente de correlación

Si valor del coeficiente de correlación

Si la variable

Precaución: El coeficiente de correlación

Ejemplo
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
| Observación | Salario | Escolaridad |
| 1 | 4.4567 | 6 |
| 2 | 5.77 | 7 |
| 3 | 5.9787 | 8 |
| 4 | 7.3317 | 9 |
| 5 | 7.3182 | 10 |
| 6 | 6.5844 | 11 |
| 7 | 7.8182 | 12 |
| 8 | 7.8351 | 13 |
| 9 | 11.0223 | 14 |
| 10 | 10.6738 | 15 |
| 11 | 10.8361 | 16 |
| 12 | 13.615 | 17 |
| 13 | 13.531 | 18 |
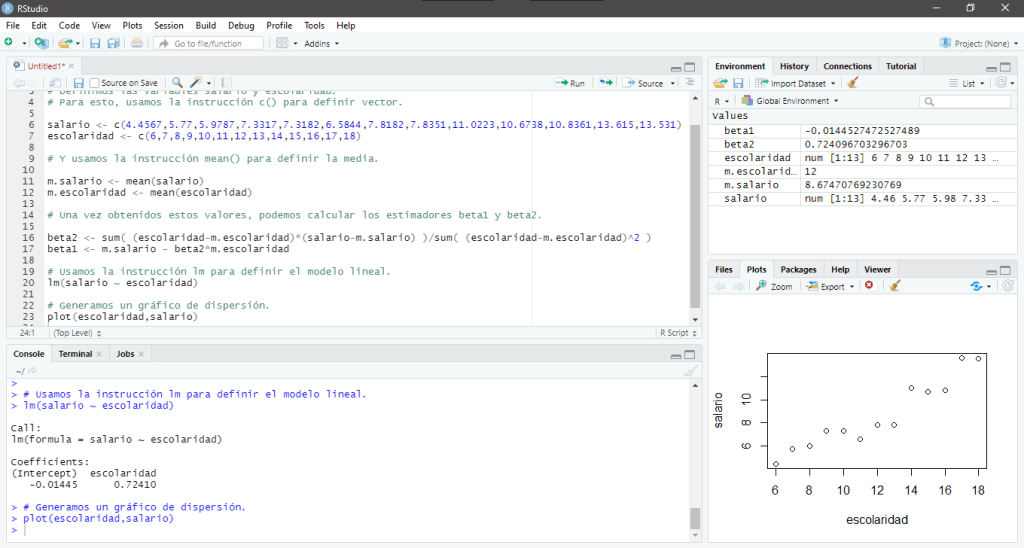
Una vez que hemos calculado el modelo lineal que define este conjunto de datos, podemos calcular el coeficiente de determinación para ver qué tan relacionadas están las variables Salario y Escolaridad, para esto, usamos la siguiente sintaxis:
r <- sum((escolaridad-m.escolaridad)*(salario-m.salario))/sqrt(sum((escolaridad - m.escolaridad)^2)*sum((salario - m.salario)^2))Al ejecutar estas instrucciones obtenemos coeficiente de correlación
En su pantalla debería aparecer:

En este caso, el valor del coeficiente de correlación sugiere que la variable


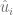 pueden ser positivos o negativos, gráficamente, podemos decir que algunas observaciones estarán por encima de la línea de regresión y otras por debajo.
pueden ser positivos o negativos, gráficamente, podemos decir que algunas observaciones estarán por encima de la línea de regresión y otras por debajo.
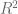 (regresión múltiple) es una medida comprendida que dice que tan bien se ajusta la línea de regresión muestral a los datos.
(regresión múltiple) es una medida comprendida que dice que tan bien se ajusta la línea de regresión muestral a los datos.




 , que expresado en forma de desviación, es decir, como la diferencia de cada observación con la media,
, que expresado en forma de desviación, es decir, como la diferencia de cada observación con la media,




 y
y  .
.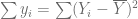 es la variación total de los valores reales de Y respecto de su media muestral, que puede denominarse la suma de cuadrados total (SCT).
es la variación total de los valores reales de Y respecto de su media muestral, que puede denominarse la suma de cuadrados total (SCT). es la variación de los valores de Y estimados alrededor de su media, que apropiadamente puede llamarse la suma de cuadrados debida a la regresión (es decir, debida a la variable explicativa), o explicada por ésta, o simplemente la suma de cuadrados explicada (SCE).
es la variación de los valores de Y estimados alrededor de su media, que apropiadamente puede llamarse la suma de cuadrados debida a la regresión (es decir, debida a la variable explicativa), o explicada por ésta, o simplemente la suma de cuadrados explicada (SCE). es la la variación residual o no explicada de los valores de Y alrededor de la línea de regresión, o sólo la suma de cuadrados de los residuos (SCR).
es la la variación residual o no explicada de los valores de Y alrededor de la línea de regresión, o sólo la suma de cuadrados de los residuos (SCR).


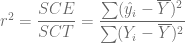


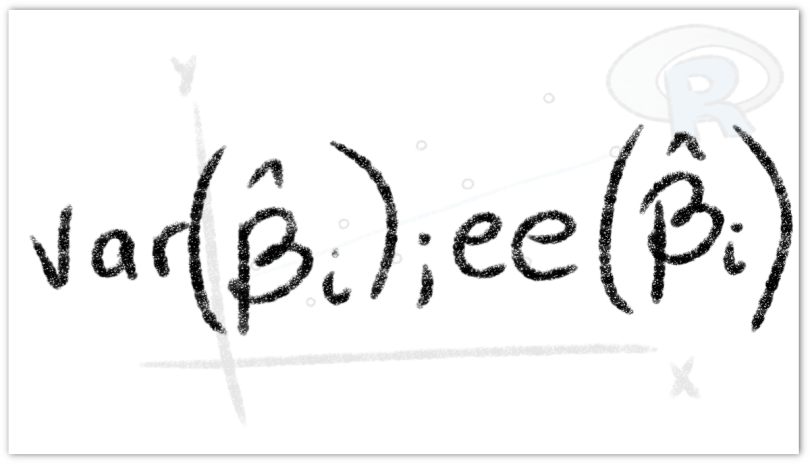
 y
y 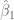 , sin embargo, al estar estos valores condicionados a la muestra que se tome, es probable que entre una muestra y otra, estos valores presenten variaciones. Entonces, surge la pregunta: ¿de qué forma podemos garantizar precisión en las estimaciones? O al menos, ¿podemos medir la imprecisión de estas?
, sin embargo, al estar estos valores condicionados a la muestra que se tome, es probable que entre una muestra y otra, estos valores presenten variaciones. Entonces, surge la pregunta: ¿de qué forma podemos garantizar precisión en las estimaciones? O al menos, ¿podemos medir la imprecisión de estas?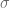 es la desviación estándar:
es la desviación estándar:
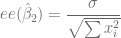


 , pues este valor se obtiene a partir de la población pero sólo contamos con una muestra, afortunadamente, podemos definir una fórmula que nos estima a través de del Método de Mínimos Cuadrados Ordinarios a la verdadera pero desconocida
, pues este valor se obtiene a partir de la población pero sólo contamos con una muestra, afortunadamente, podemos definir una fórmula que nos estima a través de del Método de Mínimos Cuadrados Ordinarios a la verdadera pero desconocida 
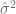 se conoce como el error estándar de estimación o el error estándar de la regresión (eee). No es más que la desviación estándar de los valores
se conoce como el error estándar de estimación o el error estándar de la regresión (eee). No es más que la desviación estándar de los valores 
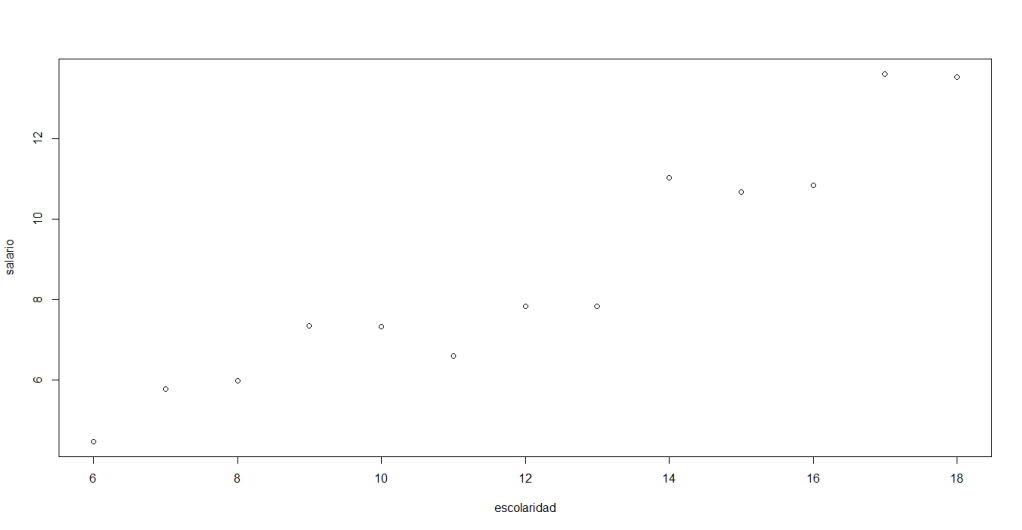

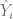 , podemos determinar los residuos usando la siguiente sintaxis:
, podemos determinar los residuos usando la siguiente sintaxis: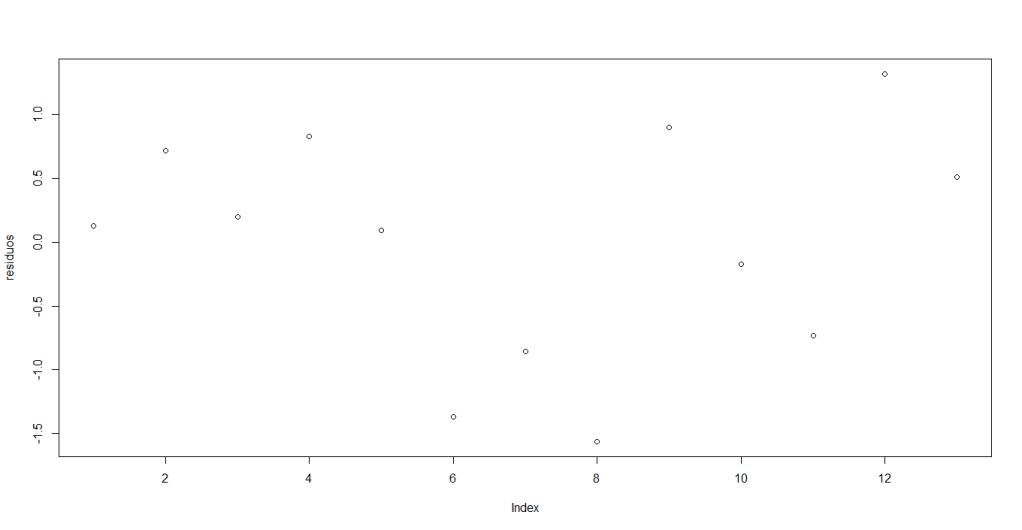

Debe estar conectado para enviar un comentario.