Hemos visto que el coeficiente de determinación nos permite determinar en qué medida dos variables están relacionadas, pero siempre resulta de interés preguntarse si es posible determinar la forma en que estas dos variables están relacionadas, particularmente, en qué medida están correlacionadas.
También pudiera interesarte
Coeficiente de Correlación Muestral
Considerando una de las fórmulas para calcular el coeficiente de determinación , definimos un nuevo valor que está íntimamente relacionado con dicha fórmula pero que conceptualmente son diferentes. Entonces, partiendo del hecho que,
Definimos un nuevo valor , conocido como el Coeficiente de Correlación Muestral, que mide el grado de asociación lineal entre dos variables y se calcula de la siguiente forma:
Podemos calcularlo en R usando la siguiente sintaxis:
r <- sum((X-m.X)*(Y-m.Y))/sqrt(sum((X - m.X)^2)*sum((Y - m.Y)^2))
Es importante destacar que:
Aunque el coeficiente de correlación r es una medida de asociación lineal entre dos variables, este no implica necesariamente alguna relación causa-efecto.
Una ventaja en el cálculo de este coeficiente, es que es simétrico por la forma en que está definido, es decir, el coeficiente de correlación entre y () es el mismo que entre y ().
Interpretación Gráfica del Coeficiente de Correlación Muestral
A diferencia de , que está acotado por 0 y 1; el coeficiente de correlación muestral está acotado por -1 y 1, esto quiere decir que puede tomar valores negativos. Entonces, considerando que gráficamente es independiente del origen y de la escala, podemos considerar varias observaciones sobre este valor:
Si valor del coeficiente de correlación es exactamente igual a 1 (uno positivo), los datos están representados gráficamente sobre una línea recta creciente.
Si valor del coeficiente de correlación es exactamente igual a -1 (uno negativo), los datos están representados gráficamente sobre una línea recta decreciente.
Si valor del coeficiente de correlación está cercano a 1 (uno positivo), los datos representados gráficamente, tienen una clara tendencia lineal creciente pero no están exactamente alineados.
Si valor del coeficiente de correlación está cercano a -1 (uno negativo), los datos representados gráficamente, tienen una clara tendencia lineal decreciente pero no están exactamente alineados.
Si valor del coeficiente de correlación está cercano a 0 pero es positivo, los datos representados gráficamente, tienen una tendencia lineal creciente pero presentan una dispersión mayor a media que el valor de está más cercano a cero.
Si valor del coeficiente de correlación está cercano a 0 pero es negativo, los datos representados gráficamente, tienen una tendencia lineal decreciente pero presentan una dispersión mayor a media que el valor de está más cercano a cero.
Si la variable y la variable son estadísticamente independientes, entonces valor del coeficiente de correlación es igual a cero y en este caso, los datos representados gráficamente, no presentan ningún tipo de tendencia lineal.
Precaución: El coeficiente de correlación es una medida de asociación lineal (o dependencia lineal) solamente; su uso en la descripción de relaciones no lineales no tiene significado. Dicho esto, puede ocurrir que sea igual a cero pero el conjunto de datos presente otro tipo de relación.
Ejemplo
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
Observación
Salario
Escolaridad
1
4.4567
6
2
5.77
7
3
5.9787
8
4
7.3317
9
5
7.3182
10
6
6.5844
11
7
7.8182
12
8
7.8351
13
9
11.0223
14
10
10.6738
15
11
10.8361
16
12
13.615
17
13
13.531
18
Tabla 3.2
Una vez que hemos calculado el modelo lineal que define este conjunto de datos, podemos calcular el coeficiente de determinación para ver qué tan relacionadas están las variables Salario y Escolaridad, para esto, usamos la siguiente sintaxis:
r <- sum((escolaridad-m.escolaridad)*(salario-m.salario))/sqrt(sum((escolaridad - m.escolaridad)^2)*sum((salario - m.salario)^2))
Al ejecutar estas instrucciones obtenemos coeficiente de correlación , que en este caso es igual a 0.9527809.
En su pantalla debería aparecer:
En este caso, el valor del coeficiente de correlación sugiere que la variable y la variable definen un tendencia lineal creciente y es lo que se puede observar en el gráfico de dispersión.
Una vez que hemos calculado la función de regresión muestral como un modelo lineal a partir de un conjunto de datos, podemos notar en su gráfica que las observaciones no necesariamente caen sobre la línea que describe dicha función y aunque esta sería situación ideal (pues así podemos describir con precisión todo el conjunto de datos usando una función), esto no ocurre en la realidad.
También pudiera interesarte
La bondad de ajuste
Considerando el siguiente gráfico, si todas las observaciones cayeran en la línea de regresión, obtendríamos lo que se conoce como un ajuste perfecto, pero rara vez se presenta este caso. Por lo general los valores de pueden ser positivos o negativos, gráficamente, podemos decir que algunas observaciones estarán por encima de la línea de regresión y otras por debajo.
Aunque se tiene la esperanza de que los residuos alrededor de la línea de regresión sean lo más pequeños posibles, el coeficiente de determinación (caso de dos variables) o (regresión múltiple) es una medida comprendida que dice que tan bien se ajusta la línea de regresión muestral a los datos.
Antes de mostrar cómo calcular , consideremos Diagramas de Venn para entender qué representa el valor de , de forma que: el círculo , representa la variación en la variable dependiente ; el círculo , la variación en la variable explicativa .
Si estos dos círculos no se intersectan, entonces la variación en no es explicada por la variación en . El valor de que representa esta situación, es
La intersección de los dos círculos (el área sombreada) indica la medida en la cual la variación en se explica por la variación en .
Entre mayor sea el área de la intersección, mayor será la variación en que se explica por la variación de . es tan sólo una medida numérica de esta intersección y generalmente es un valor entre 0 y 1.
Si estos dos círculos se intersectan en su totalidad, es decir, son iguales, entonces la variación en está explicada en su totalidad por la variación de la variable . El valor de que representa esta situación, es
Para calcular , partimos del hecho que , que expresado en forma de desviación, es decir, como la diferencia de cada observación con la media,
Al elevar al cuadrado esta última ecuación en ambos lados y sumar sobre la muestra, obtenemos
Esa última igualdad se debe a que y .
Las diversas sumas de cuadrados en esta ecuación se describen de la siguiente manera:
es la variación total de los valores reales de Y respecto de su media muestral, que puede denominarse la suma de cuadrados total (SCT).
es la variación de los valores de Y estimados alrededor de su media, que apropiadamente puede llamarse la suma de cuadrados debida a la regresión (es decir, debida a la variable explicativa), o explicada por ésta, o simplemente la suma de cuadrados explicada (SCE).
es la la variación residual o no explicada de los valores de Y alrededor de la línea de regresión, o sólo la suma de cuadrados de los residuos (SCR).
Por lo tanto, podemos reescribir la última ecuación de la siguiente manera:
Demostrando así, que la variación total en los valores observados alrededor del valor de su media puede dividirse en dos partes, una atribuible a la línea de regresión y la otra a fuerzas aleatorias, pues no todas las observaciones caen sobre la línea ajustada.
Dividiendo esta ecuación, entre la SCT a ambos lados tenemos que
Finalmente, definimos el coeficiente de determinación como
Podemos calcularlo en R usando la siguiente sintaxis:
r2 <- sum((Y.e - m.Y)^2)/sum((Y - m.Y)^2)
También podemos definir el coeficiente de determinación como
Podemos calcularlo en R usando la siguiente sintaxis:
r2 <- 1 - sum((Y - Y.e)^2)/sum((Y - m.Y)^2)
Ejemplo
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
Observación
Salario
Escolaridad
1
4.4567
6
2
5.77
7
3
5.9787
8
4
7.3317
9
5
7.3182
10
6
6.5844
11
7
7.8182
12
8
7.8351
13
9
11.0223
14
10
10.6738
15
11
10.8361
16
12
13.615
17
13
13.531
18
Tabla 3.2
Una vez que hemos calculado el modelo lineal que define este conjunto de datos, podemos calcular el coeficiente de determinación para ver qué tan relacionadas están las variables Salario y Escolaridad, para esto, usamos la siguiente sintaxis:
Al ejecutar estas instrucciones obtenemos coeficiente de determinación , que en este caso es igual a 0.9077914.
En su pantalla debería aparecer:
En este caso, el valor del coeficiente de determinación sugiere que la variación en está explicada casi en su totalidad por la variación de la variable .
El Método de los Mínimos Cuadrados Ordinarios (MCO) nos provee una forma estimar los parámetros y , sin embargo, al estar estos valores condicionados a la muestra que se tome, es probable que entre una muestra y otra, estos valores presenten variaciones. Entonces, surge la pregunta: ¿de qué forma podemos garantizar precisión en las estimaciones? O al menos, ¿podemos medir la imprecisión de estas?
También pudiera interesarte
La varianza muestral y el error estándar
La teoría estadística provee una forma de medir la precisión de un valor estimado, esto es, el error estándar (ee) que está definido como la desviación estándar de la distribución muestral del estimador. Es importante recalcar que al hablar sólo de desviación estándar, hacemos referencia a la población, en cambio, al hablar del error estándar, hacemos referencia a la muestra de dicha población.
Considerando la varianza muestral, que mide la variabilidad de los datos respecto a su media; podemos calcular el error estándar al tomar la raíz cuadrada de esta. Entonces, si es la desviación estándar:
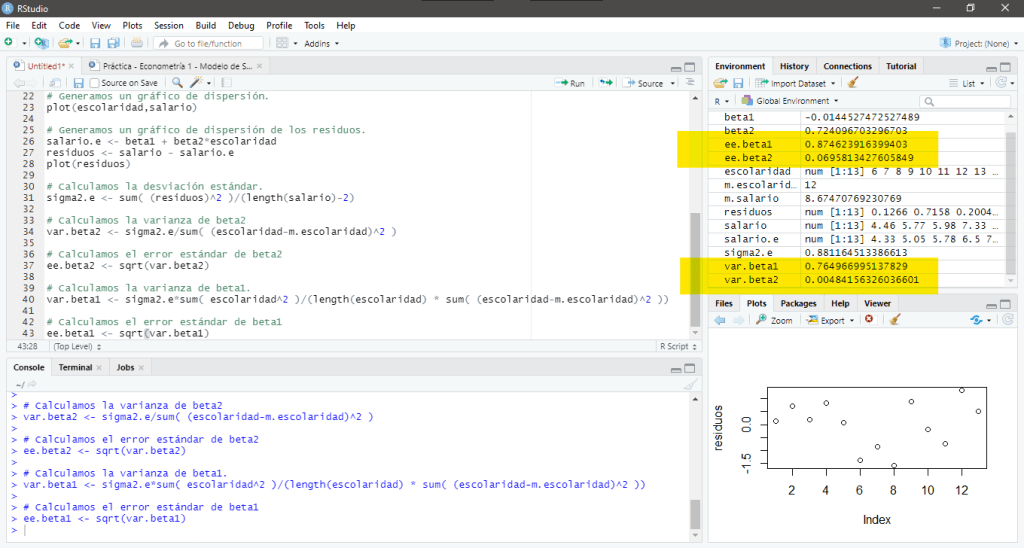
Calculamos la varianza y el error estándar del parámetro usando las siguientes fórmulas respectivamente,
Podemos calcular la varianza y el error estándar del parámetro en R usando la siguiente sintaxis:
La desviación estándar estimada y el error estándar de estimación
Si bien contamos con los datos para calcular parte de estas expresiones, aún desconocemos el valor de , pues este valor se obtiene a partir de la población pero sólo contamos con una muestra, afortunadamente, podemos definir una fórmula que nos estima a través de del Método de Mínimos Cuadrados Ordinarios a la verdadera pero desconocida, esta fórmula es
Podemos calcular la desviación estándar estimada en R usando la siguiente sintaxis:
sigma2.e <- sum(res^2)/(lenght(X)-2)
Vale la pena destacar que la raíz cuadrada de se conoce como el error estándar de estimación o el error estándar de la regresión (eee). No es más que la desviación estándar de los valores alrededor de la línea de regresión estimada, la cual suele servir como medida para resumir la bondad del ajuste de dicha línea. Se calcula de la siguiente manera
Podemos calcular este valor en R usando la siguiente sintaxis:
ee.e <- sqrt(sigma2.e)
Ejemplo
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
Observación
Salario
Escolaridad
1
4.4567
6
2
5.77
7
3
5.9787
8
4
7.3317
9
5
7.3182
10
6
6.5844
11
7
7.8182
12
8
7.8351
13
9
11.0223
14
10
10.6738
15
11
10.8361
16
12
13.615
17
13
13.531
18
Tabla 3.2
Una vez que hemos calculado el modelo lineal que define este conjunto de datos, podemos determinar el error estándar de los parámetros estimados, pero primero debemos estimar la desviación estándar usando la siguiente sintaxis:
Antes de empezar a definir un modelo sobre un conjunto de datos, es importante conocer el comportamiento de una variable respecto a otra pues de esta forma, podemos hacernos una idea de cual es el modelo más adecuado para describirlo.
También pudiera interesarte
Diagrama de Dispersión
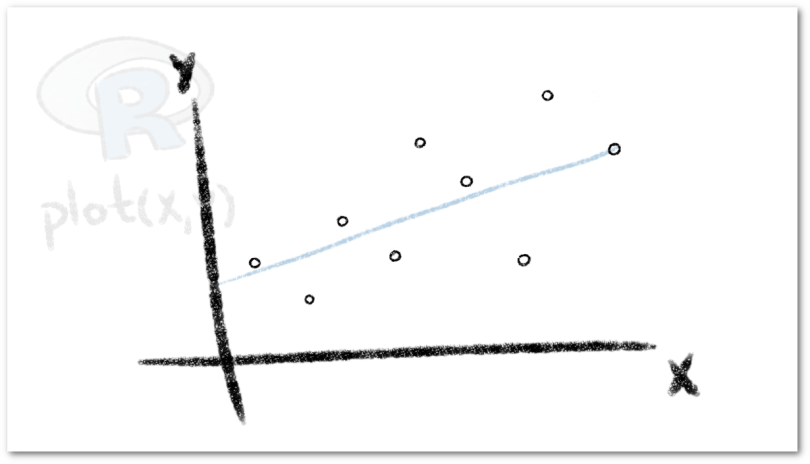
Una de las formas más directas y sencillas para estudiar la forma en que se relacionan dos variables es usando un diagrama de dispersión. Si consideramos dos variables de un conjunto de datos, digamos una variable exógenax y una variable endógena y, un Diagrama de Dispersión (o Gráfico de Dispersión) consiste en ubicar en el plano cartesiano cada par ordenado formado por los elementos de estas dos variables. Ubicando la variable exógena en el eje horizontal y la variable endógena en el eje vertical.
De esta forma, si nuestro objetivo es definir un Modelo de Regresión Lineal, ubicamos en el eje horizontal, los valores de la variable y en el eje vertical, los valores de la variable . Podemos generar un diagrama de dispersión en R recurriendo a la instrucción plot y usamos la siguiente sintaxis:
plot(X,Y)
Ejemplo
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
Observación
Salario
Escolaridad
1
4.4567
6
2
5.77
7
3
5.9787
8
4
7.3317
9
5
7.3182
10
6
6.5844
11
7
7.8182
12
8
7.8351
13
9
11.0223
14
10
10.6738
15
11
10.8361
16
12
13.615
17
13
13.531
18
Tabla 3.2
Para generar un diagrama de dispersión que nos ayude a estudiar como el nivel de estudios afecta el salario de una persona, entonces: la variable Escolaridad será nuestra variable exógena y será ubicada en el eje horizontal; la variable Salario será nuestra variable endógena y será ubicada en el eje vertical.
Recurriremos a la instrucción plot para generar un diagrama de dispersión y usamos la siguiente sintaxis:
plot(escolaridad,salario)
Al ejecutar esta instrucción, aparecerá de forma inmediata el siguiente gráfico:
En su pantalla debería aparecer lo siguiente:
También es posible dibujar sobre el diagrama de dispersión la Recta de Regresión, para esto recurrimos a la instrucción abline(), usamos la siguiente sintaxis para generar la recta definida por $\hat{Y} = \hat{\beta}_1 + \hat{\beta}_2 X$:
abline(lm(Y ~ X))
Anuncios
Ejemplo para los residuos
Si bien los diagramas de dispersión nos ayudan a estudiar el comportamiento de dos variables, también nos ayudan a estudiar el comportamiento de los residuos. Uno de los supuestos para del Modelo Clásico de Regresión Lineal, estipula que no debe haber autocorrelación, esto quiere decir que la correlación de los residuos debe ser nula.
A partir de la forma en que está definido el modelo lineal, podemos calcular los residuos usando la siguiente fórmula:
Entonces, si calculamos cada uno de los valores estimados , podemos determinar los residuos usando la siguiente sintaxis:
Y.e <- beta1 + beta2*X
res <- Y - Y.e
Usamos la instrucción plot(res) para generar un gráfico de dispersión de los residuos tomando en cuenta que en el eje horizontal se ubica el número de observación y en el vertical el residuo correspondiente. Un indicador de no autocorrelación es que el gráfico de dispersión no presente ningún patrón de comportamiento, en términos coloquiales: que estén todos a lo loco.
Continuando con nuestro ejemplo, generamos un gráfico usando la siguiente sintaxis:
Al ejecutar estas instrucciones, aparecerá de forma inmediata el siguiente gráfico:
En su pantalla debería aparecer:
Aunque pareciera no haber ningún patrón, no podemos asegurar no hay autocorrelación, también hay que considerar que el tamaño de la muestra es pequeño así que las afirmaciones que se hagan sobre el comportamiento que describe el modelo lineal puede ser impreciso.
El análisis de regresión sienta la base para los estudios econométricos y a su vez, estos se fundamentan formulando modelos lineales con dos variables: una independiente y otra dependiente; este tipo de modelos definen rectas, es decir, aquellos que se expresan de la siguiente forma:
También pudiera interesarte
Linealidad
Al mencionar la linealidad en una relación entre variables, siempre es importante especificar respecto a qué elemento de la relación, es dicha relación, lineal. Formalmente, diremos que una relación es lineal respecto a un elemento de la ecuación, si dicho elemento no está siendo multiplicada por sí mismo o si permanece inalterado por alguna función en la expresión, por ejemplo, la siguiente ecuación
Es una ecuación lineal respecto respecto la variable y el parámetro , debido a que estos dos elementos permanecen inalterados. Sin embargo, no es lineal respecto al parámetro pues este está multiplicado por sí mismo, tampoco es lineal respecto a la variable pues esta está alterada por la función logaritmo neperiano.
La linealidad respecto a los parámetros representa una base en la que se fundamentan los Modelos Lineales que estudiaremos. Es por esto que, usualmente, el término regresión lineal hace referencia a la linealidad de los parámetros. Por lo tanto, puede o no ser lineal en las variables.
El Modelo de Regresión Lineal
Todo estudio de índole estadístico está sometido a un error de aproximación y la econometría no escapa de esta característica, de forma que, al efectuar un censo poblacional, se puede estimar un modelo definido por la Función de Regresión Poblacional (FRP), expresado de la siguiente manera:
Sin embargo, llevar a cabo un censo puede resultar costoso en todos los aspectos, es por esto que se recurre a muestras poblacionales, a partir de las cuales se puede estimar un modelo definido por la Función de Regresión Muestral (FRM), expresado de la siguiente manera:
Y si bien el objetivo principal del análisis de regresión es estimar la FRP con base en la FRM, siempre se debe tomar en cuenta que: debido a fluctuaciones muestrales, la estimación de la FRP basada en la FRM es, en el mejor de los casos, una aproximación.
Mínimos Cuadrados Ordinarios (MCO)
Entonces, los valores de y se pueden estimar a partir de una muestra, usando un modelo que cuente con el término de error más pequeño posible, sin embargo, no podemos permitir que estos errores se anulen.
El Método de los Mínimos Cuadrados Ordinarios (MCO) que consiste en considerar, de todos los modelos posibles, el modelo tal que la suma de los cuadrados de los residuos sea la más pequeña, es decir, tal que la siguiente suma sea la más pequeña:
Llevando a cabo los cálculos necesarios para que esto se cumpla, se determina que los valores que estiman a y , es decir, los estimadores y se calculan de la siguiente forma:
El valor se conoce como la pendiente y su estimador es:
El valor se conoce como el intercepto y su estimador es:
Conociendo estas dos expresiones, podemos hacer los cálculos correspondientes en R, pues calculando la media de las variables y , usamos la siguiente sintaxis para calcular los estimadores
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
Observación
Salario
Escolaridad
1
4.4567
6
2
5.77
7
3
5.9787
8
4
7.3317
9
5
7.3182
10
6
6.5844
11
7
7.8182
12
8
7.8351
13
9
11.0223
14
10
10.6738
15
11
10.8361
16
12
13.615
17
13
13.531
18
Tabla 3.2
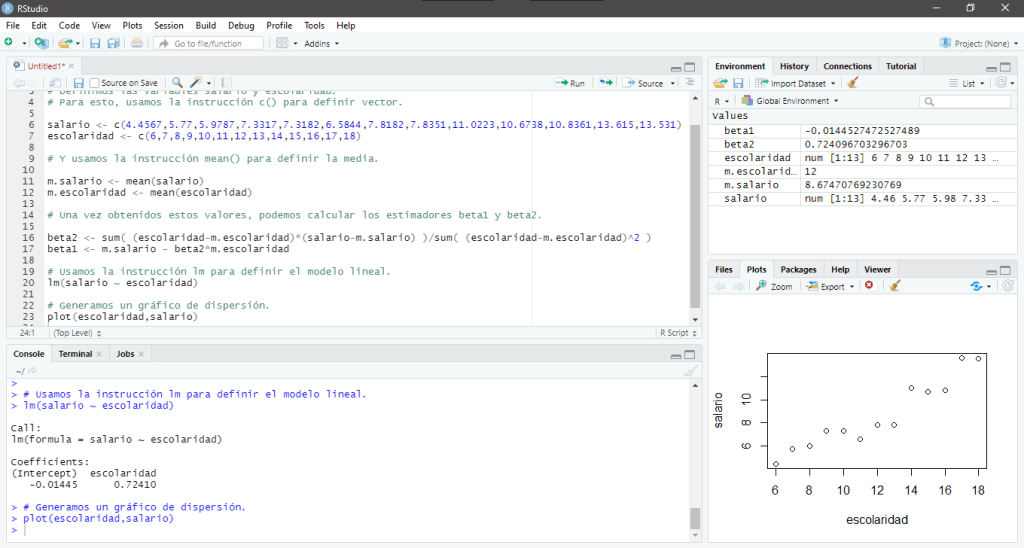
Si queremos definir un modelo que describa el salario de una persona en función del nivel de estudio que esta persona tenga, empezamos por definir las variables salario y escolaridad, usando las siguientes instrucciones:
Al ejecutar estas instrucciones definimos las variables y podemos ver los valores que cada una de ellas tienen, particularmente la de los estimadores que son las que nos interesan.
Mi recomendación es usar el símbolo de numeral «#» para hacer comentarios en el script y mantener orden en las instrucciones que escribimos o entender porqué las escribimos, les comparto como haría yo estas anotaciones.
Habiendo calculado los valores de los estimadores, concluimos que el modelo lineal determinado por el método de los Mínimos Cuadrados Ordinarios, que estima el comportamiento de los valores expuestos en la Tabla 3.2 es el siguiente:
Anuncios
La instrucción lm
También podemos recurrir a la instrucción lm para definir un modelo lineal, de forma que si queremos definir a la variable en función de la variable , entonces usamos la siguiente sintaxis:
lm(Y ~ X)
Note que se ha usado la virguilla (~) para definir la relación entre las dos variables. Entonces, continuando con nuestro ejemplo, podemos definir el modelo lineal que describe el Salario en función de la Escolaridad usando la siguiente sintaxis:
lm(salario ~ escolaridad)
Al ejecutar esta instrucción, en la consola deberá aparecer lo siguiente:


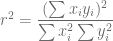


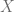













 pueden ser positivos o negativos, gráficamente, podemos decir que algunas observaciones estarán por encima de la línea de regresión y otras por debajo.
pueden ser positivos o negativos, gráficamente, podemos decir que algunas observaciones estarán por encima de la línea de regresión y otras por debajo.
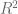 (regresión múltiple) es una medida comprendida que dice que tan bien se ajusta la línea de regresión muestral a los datos.
(regresión múltiple) es una medida comprendida que dice que tan bien se ajusta la línea de regresión muestral a los datos.




 , que expresado en forma de desviación, es decir, como la diferencia de cada observación con la media,
, que expresado en forma de desviación, es decir, como la diferencia de cada observación con la media,




 y
y  .
.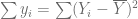 es la variación total de los valores reales de Y respecto de su media muestral, que puede denominarse la suma de cuadrados total (SCT).
es la variación total de los valores reales de Y respecto de su media muestral, que puede denominarse la suma de cuadrados total (SCT). es la variación de los valores de Y estimados alrededor de su media, que apropiadamente puede llamarse la suma de cuadrados debida a la regresión (es decir, debida a la variable explicativa), o explicada por ésta, o simplemente la suma de cuadrados explicada (SCE).
es la variación de los valores de Y estimados alrededor de su media, que apropiadamente puede llamarse la suma de cuadrados debida a la regresión (es decir, debida a la variable explicativa), o explicada por ésta, o simplemente la suma de cuadrados explicada (SCE). es la la variación residual o no explicada de los valores de Y alrededor de la línea de regresión, o sólo la suma de cuadrados de los residuos (SCR).
es la la variación residual o no explicada de los valores de Y alrededor de la línea de regresión, o sólo la suma de cuadrados de los residuos (SCR).


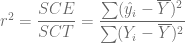


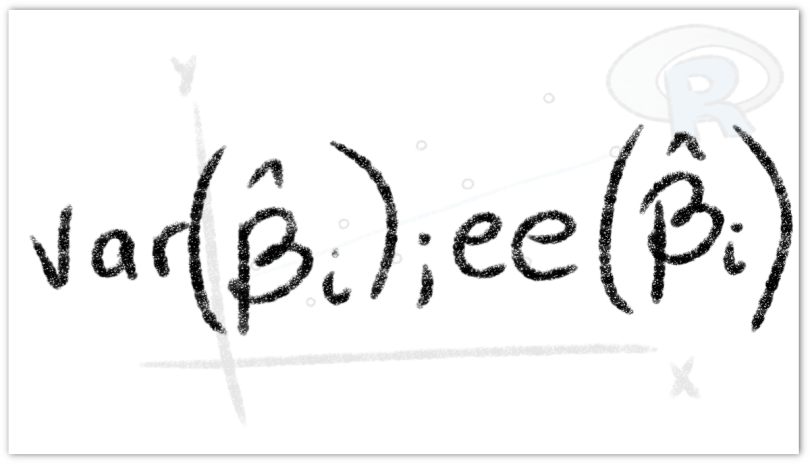
 y
y 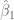 , sin embargo, al estar estos valores condicionados a la muestra que se tome, es probable que entre una muestra y otra, estos valores presenten variaciones. Entonces, surge la pregunta: ¿de qué forma podemos garantizar precisión en las estimaciones? O al menos, ¿podemos medir la imprecisión de estas?
, sin embargo, al estar estos valores condicionados a la muestra que se tome, es probable que entre una muestra y otra, estos valores presenten variaciones. Entonces, surge la pregunta: ¿de qué forma podemos garantizar precisión en las estimaciones? O al menos, ¿podemos medir la imprecisión de estas?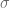 es la desviación estándar:
es la desviación estándar:
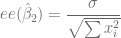


 , pues este valor se obtiene a partir de la población pero sólo contamos con una muestra, afortunadamente, podemos definir una fórmula que nos estima a través de del Método de Mínimos Cuadrados Ordinarios a la verdadera pero desconocida
, pues este valor se obtiene a partir de la población pero sólo contamos con una muestra, afortunadamente, podemos definir una fórmula que nos estima a través de del Método de Mínimos Cuadrados Ordinarios a la verdadera pero desconocida 
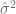 se conoce como el error estándar de estimación o el error estándar de la regresión (eee). No es más que la desviación estándar de los valores
se conoce como el error estándar de estimación o el error estándar de la regresión (eee). No es más que la desviación estándar de los valores 
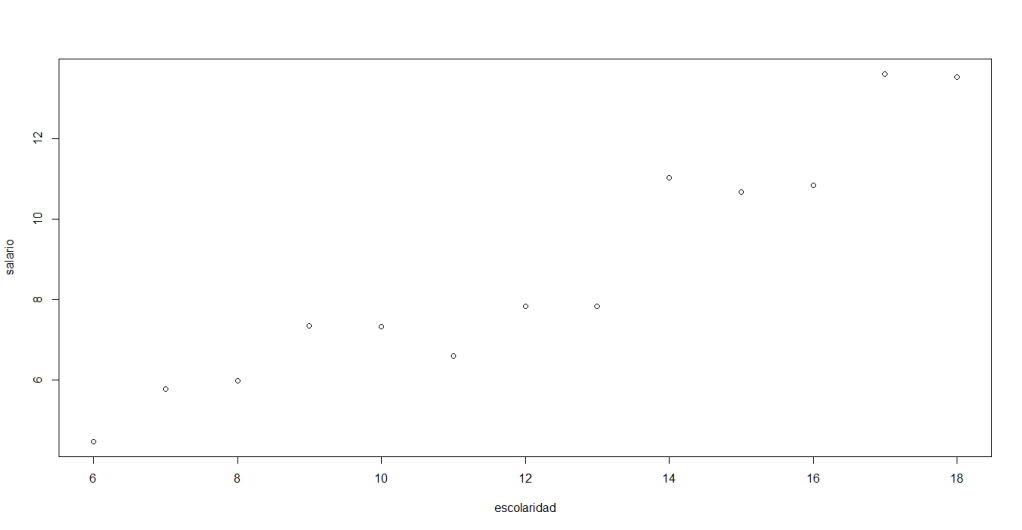

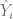 , podemos determinar los residuos usando la siguiente sintaxis:
, podemos determinar los residuos usando la siguiente sintaxis: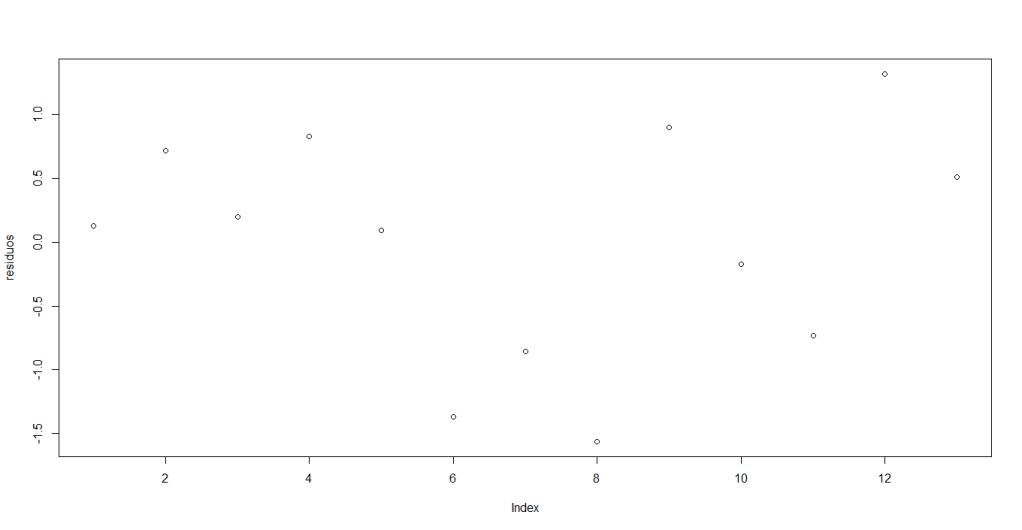

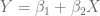

 , debido a que estos dos elementos permanecen inalterados. Sin embargo, no es lineal respecto al parámetro
, debido a que estos dos elementos permanecen inalterados. Sin embargo, no es lineal respecto al parámetro 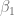 pues este está multiplicado por sí mismo, tampoco es lineal respecto a la variable
pues este está multiplicado por sí mismo, tampoco es lineal respecto a la variable 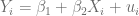








Debe estar conectado para enviar un comentario.