
R provee un lenguaje de programación para que sus usuarios puedan crear de la nada scripts para llevar a cabo tareas titánicas, es por esto que nos debemos familiarizar con algunos de los elementos más básicos de sus instrucciones y la sintaxis correspondiente.
También pudiera interesarte
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
| Observación | Salario | Escolaridad |
| 1 | 4.4567 | 6 |
| 2 | 5.77 | 7 |
| 3 | 5.9787 | 8 |
| 4 | 7.3317 | 9 |
| 5 | 7.3182 | 10 |
| 6 | 6.5844 | 11 |
| 7 | 7.8182 | 12 |
| 8 | 7.8351 | 13 |
| 9 | 11.0223 | 14 |
| 10 | 10.6738 | 15 |
| 11 | 10.8361 | 16 |
| 12 | 13.615 | 17 |
| 13 | 13.531 | 18 |
Vectores
Si queremos trabajar con este conjunto de datos, es necesario almacenarlos en la memoria de nuestro espacio de trabajo y la forma más básica para hacer esto es usando vectores. Los vectores son la estructura de datos más simple en R y representan una secuencia de elementos del mismo tipo (de acuerdo con la web datasicience+).
Si queremos definir un vector a partir de una variable x que cuenta con n observaciones, la sintaxis correspondiente es
c(x_1,x_2,...,x_n)En nuestro caso, debemos definir un vectores que alberguen datos numéricos, y considerando nuestro conjunto de datos:
Para definir una variable llamada obs que albergue la información del vector que consisten en los elementos de la variable Observación, escribimos lo siguiente:
obs <- c(1,2,3,4,5,6,7,8,9,10,11,12,13)Para definir una variable llamada salario que albergue la información del vector que consisten en los elementos de la variable Salario, escribimos lo siguiente:
salario <- c(4.4567,5.77,5.9787,7.3317,7.3182,6.5844,7.8182,7.8351,11.0223,10.6738,10.8361,13.615,13.531)Para definir una variable llamada escolaridad que albergue la información del vector que consisten en los elementos de la variable Escolaridad, escribimos lo siguiente:
escolaridad <- c(6,7,8,9,10,11,12,13,14,15,16,17,18)Instrucciones
Llevar a cabo ciertos cálculos resulta tedioso cuando la cantidad de elementos involucrados es muy grande, afortunadamente, podemos indicarle a R que haga estos cálculos por nosotros a través de las instrucciones (también llamadas comandos, como un anglicismo de la palabra commands).
La suma de los elementos de un vector
Una vez que hemos definido variables a partir de vectores, podemos dar nuestros primeros pasos para trabajar con con los datos de nuestra tabla. Empecemos con algo básico como calcular la suma de los elementos de un vector, que pudiéramos calcularla sumando cada uno de los elementos usando las operaciones básicas de R.
Sin embargo, R provee una instrucción que permite efectuar la suma de todos los elementos de un vector. Entonces, si x es una variable definida por un vector que alberga valores numéricos, la sintaxis correspondiente es
sum(x)Considerando las variables salario y escolaridad que hemos definido anteriormente, podemos calcular la suma de las observaciones de cada variable usando, de forma respectiva, las siguientes instrucciones
sum(salario)sum(escolaridad)Al ejecutar estas instrucciones, aparecerá de forma inmediata la siguiente información en la consola:
> sum(salario)
[1] 112.7712
> sum(escolaridad)
[1] 156
La longitud de un vector
Al hacer estudios estadísticos siempre es importante determinar la cantidad de observaciones con las que se cuentan y la instrucción que nos permite determinar esta cantidad es conocida como la longitud del vector que alberga la información. Entonces, si x es una variable definida por un vector que alberga valores numéricos, la sintaxis correspondiente es
length(x)Considerando las variables salario y escolaridad que hemos definido anteriormente, podemos calcular la cantidad de observaciones de cada variable usando, de forma respectiva, las siguientes instrucciones
length(salario)length(escolaridad)Al ejecutar estas instrucciones, aparecerá de forma inmediata la siguiente información en la consola:
> length(salario)
[1] 13
> length(escolaridad)
[1] 13
La media
La media de una variable sienta la base para la estadística descriptiva y de ahí radica la importancia de aprender a calcularla. Esta se calcula con el cociente de la suma de todas las observaciones entre la cantidad de observaciones, de forma que si tenemos una variable 

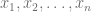
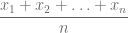
Por lo tanto, podemos combinar las instrucciones de suma y longitud de un vector para calcular la media. Entonces, si x es una variable definida por un vector que alberga valores numéricos, la sintaxis correspondiente es
sum(x)/length(x)Muy bien, de esta forma podemos calcular la media de una variable, pero debido al extenso uso de la media para los cálculos estadísticos, R provee una instrucción específica para calcularla y la sintaxis correspondiente es:
mean(x)Considerando las variables salario y escolaridad que hemos definido anteriormente, podemos calcular la media de cada variable usando, de forma respectiva, las siguientes instrucciones
mean(salario)mean(escolaridad)Al ejecutar estas instrucciones, aparecerá de forma inmediata la siguiente información en la consola:
> mean(salario)
[1] 8.674708
> mean(escolaridad)
[1] 12
La varianza
La varianza de una variable representa información vital la estadística descriptiva, por lo que también es importante de aprender a calcularla. Esta se calcula con el cociente de la suma de todos cuadrados de las diferencias de las observaciones con la media, entre la cantidad de observaciones, de forma que si tenemos una variable 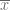
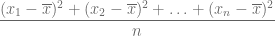
Y si bien, podemos combinar las instrucciones anteriormente descritas para hacer este cálculo, este proceso puede resultar engorroso. Afortunadamente, R provee una instrucción específica para calcularla; si x es una variable definida por un vector que alberga valores numéricos, la sintaxis correspondiente es
var(x)Considerando las variables salario y escolaridad que hemos definido anteriormente, podemos calcular la varianza de cada variable usando, de forma respectiva, las siguientes instrucciones
var(salario)var(escolaridad)Al ejecutar estas instrucciones, aparecerá de forma inmediata la siguiente información en la consola:
> var(salario)
[1] 8.759861
> var(escolaridad)
[1] 15.16667












Debe estar conectado para enviar un comentario.