
En el estudio de los fenómenos medidos de forma discreta a través del tiempo, resulta de particular interés relacionar de forma lineal lo ocurrido en el presente con lo ocurrido en el periodo inmediato anterior, es decir, lo ocurrido en un periodo 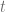
También pudiera interesarte
Ecuaciones en Diferencias Finitas Lineales de Primer Orden
Una vez que hemos aprendido a clasificar las Ecuaciones en Diferencias, podemos empezar a estudiar los métodos para calcular la solución de estas y para esto, consideremos la forma más simple que podemos obtener a partir de la forma en que las hemos clasificado, esto es Ecuaciones en Diferencias Finitas Lineales Autónomas de Primer Orden, es decir, con coeficientes constantes.
Consideremos 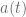



Por otra parte, consideremos 



A partir de esta igualdad, podemos manipular algebraicamente para notar que este tipo de ecuaciones se puede reescribir no como una relación implícita entre 

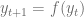

Este tipo de expresiones se les conoce como relaciones de recurrencia, pues relaciona a toda observación directamente con la observación inmediatamente anterior y usualmente se usan para describir crecimientos poblacionales. Considerando este tipo de ecuaciones, veamos cuales son las condiciones que se deben cumplir para garantizar que existe una única solución.
Teorema de Existencia y Unicidad
Sea
Si fijamos un número real 
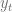
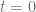

Ejemplo 1
Considere la Ecuación en Diferencias Lineal Autónoma de Primer Orden expresada de la siguiente manera con la condición inicial indicada:

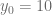
Antes desarrollar un método general que nos permita calcular la solución de este tipo de ecuaciones, veamos una idea intuitiva para calcular la solución de esta ecuación. Entonces, partiendo de la condición inicial, tenemos que
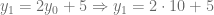
Efectuando estas últimas operaciones, podemos calcular el valor de 



Siguiendo de esta forma, podemos calcular el valor de 

Y así sucesivamente, podemos calcular los demás términos procediendo de forma recursiva. Finalmente, calculamos el término general

Entonces, sacando a 

Pero justamente, 
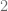


Si te ha parecido útil la información que hemos presentado en totumat y quieres ayudar a mantener este sitio en línea puedes mirar nuestros anuncios publicitarios o donar dinero a través de PayPal.
La solución general
Considerando este último ejemplo, podemos plantear una fórmula general para la solución de este tipo de ecuaciones, pues al considerar una ecuación de la forma:
Partiendo de la condición inicial 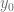
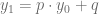
Así como pudimos calcular
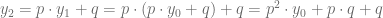
Siguiendo de esta forma, podemos calcular el valor de

Siguiendo de esta forma, podemos calcular el valor de 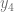

Y así sucesivamente, podemos calcular los demás términos procediendo de forma recursiva. Finalmente, calculamos el término general

Entonces, sacando a 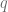

Pero justamente, 
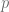


Esta última igualdad será reescrita para que posteriormente podamos identificar algunos elementos en ella, de la siguiente forma:
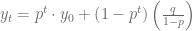
Si consideramos la expresión 


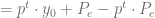
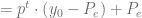
Podemos usar cualquier de estas dos últimas fórmulas para calcular la solución de cualquier ecuación en diferencias finitas expresadas de la forma 
Ejemplos
Ejemplo 2
Considere la Ecuación en Diferencias Lineal Autónoma de Primer Orden expresada de la siguiente manera con la condición inicial indicada:

Entonces, aplicando la fórmula, identificamos los valores 


Ejemplo 3
Considere la Ecuación en Diferencias Lineal Autónoma de Primer Orden expresada de la siguiente manera con la condición inicial indicada:

Notemos que 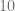

Entonces, aplicando la fórmula, identificamos los valores de 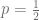



 está medida de forma continua si su dominio está definido como un intervalo en el conjunto de los números reales, formalmente, diremos que definida de la siguiente forma:
está medida de forma continua si su dominio está definido como un intervalo en el conjunto de los números reales, formalmente, diremos que definida de la siguiente forma: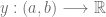


 para cualesquiera dos números reales
para cualesquiera dos números reales 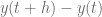
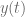 se representa como
se representa como  por la letra
por la letra 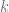 .
.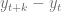
 , es decir,
, es decir,  .
.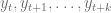 a través de una igualdad. Formalmente, una relación expresada de la siguiente forma:
a través de una igualdad. Formalmente, una relación expresada de la siguiente forma: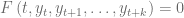
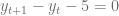 diremos que esta es una ecuación en diferencias finitas y nuestro propósito será el de determinar cuál es la forma general de la sucesión
diremos que esta es una ecuación en diferencias finitas y nuestro propósito será el de determinar cuál es la forma general de la sucesión 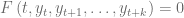

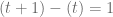 .
.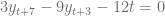
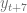 y
y 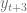 es exactamente igual a uno y tampoco hay un producto entre estos dos elementos.
es exactamente igual a uno y tampoco hay un producto entre estos dos elementos. .
.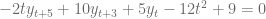
 ,
, 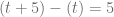 .
.
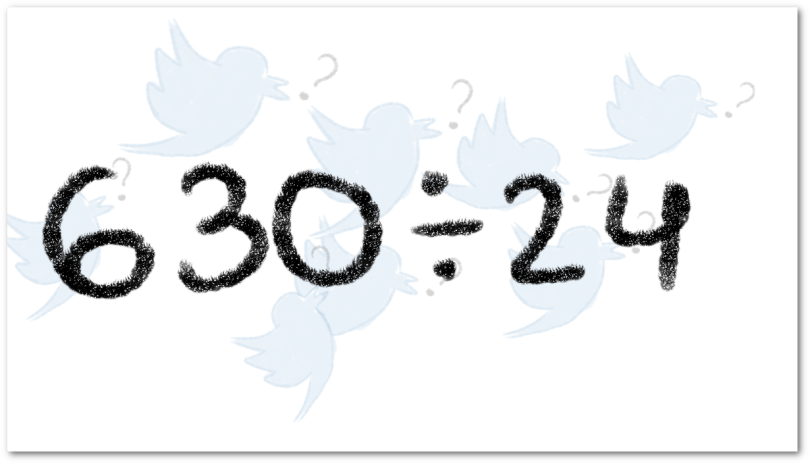
 entre
entre 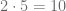 y de acuerdo con el algoritmo de la división, el resto es igual a
y de acuerdo con el algoritmo de la división, el resto es igual a 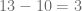 , esto lo expresamos de la siguiente forma:
, esto lo expresamos de la siguiente forma:
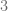 es menor que el divisor
es menor que el divisor  . En este caso el resto es distinto de cero, por lo tanto, decimos que la división no es exacta.
. En este caso el resto es distinto de cero, por lo tanto, decimos que la división no es exacta. entre
entre  , pudiéramos buscar un número entero tal que al multiplicarlo por
, pudiéramos buscar un número entero tal que al multiplicarlo por 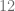 , pero si no existe este número, buscamos un resultado que esté lo más cercano posible pero menor que
, pero si no existe este número, buscamos un resultado que esté lo más cercano posible pero menor que 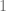 pues
pues 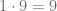 y de acuerdo con el algoritmo de la división, el resto es igual a
y de acuerdo con el algoritmo de la división, el resto es igual a  , esto lo expresamos de la siguiente forma:
, esto lo expresamos de la siguiente forma: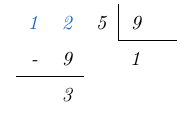
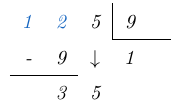
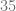 es mayor que
es mayor que 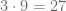 y de acuerdo con el algoritmo de la división, el resto es igual a
y de acuerdo con el algoritmo de la división, el resto es igual a 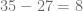 , esto lo expresamos de la siguiente forma:
, esto lo expresamos de la siguiente forma: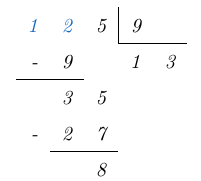
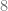 es menor que el divisor
es menor que el divisor  . En este caso el resto es distinto de cero, por lo tanto, decimos que la división no es exacta.
. En este caso el resto es distinto de cero, por lo tanto, decimos que la división no es exacta. entre
entre 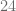 , debemos considerar que el número
, debemos considerar que el número  , pero si no existe este número, buscamos un resultado que esté lo más cercano posible pero menor que
, pero si no existe este número, buscamos un resultado que esté lo más cercano posible pero menor que  y de acuerdo con el algoritmo de la división, el resto es igual a
y de acuerdo con el algoritmo de la división, el resto es igual a  , esto lo expresamos de la siguiente forma:
, esto lo expresamos de la siguiente forma:
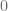 y lo escribimos del lado derecho del
y lo escribimos del lado derecho del 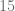 .
.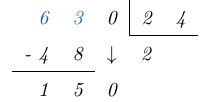
 es mayor que
es mayor que 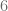 pues
pues 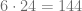 y de acuerdo con el algoritmo de la división, el resto es igual a
y de acuerdo con el algoritmo de la división, el resto es igual a 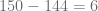 , esto lo expresamos de la siguiente forma:
, esto lo expresamos de la siguiente forma: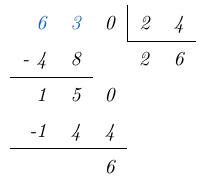
 . En este caso el resto es distinto de cero, por lo tanto, decimos que la división no es exacta.
. En este caso el resto es distinto de cero, por lo tanto, decimos que la división no es exacta.
 es de vital importancia para el análisis de regresión, pues varios de los supuestos del Modelo Clásico de Regresión Lineal (MCRL) hacen énfasis en los residuos, es por esto que se recurre a herramientas que nos permitan verificar si se cumplen estos supuestos y así, aumentar la confiabilidad sobre las conclusiones que se hagan a partir del modelo planteado.
es de vital importancia para el análisis de regresión, pues varios de los supuestos del Modelo Clásico de Regresión Lineal (MCRL) hacen énfasis en los residuos, es por esto que se recurre a herramientas que nos permitan verificar si se cumplen estos supuestos y así, aumentar la confiabilidad sobre las conclusiones que se hagan a partir del modelo planteado. está normalmente distribuida si
está normalmente distribuida si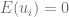



 significa distribuido,
significa distribuido,  denota distribución normal y los términos entre paréntesis representan los dos parámetros de la distribución normal: la media y la varianza, respectivamente.
denota distribución normal y los términos entre paréntesis representan los dos parámetros de la distribución normal: la media y la varianza, respectivamente.

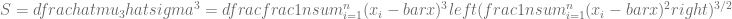 y
y 
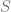 ) y la curtosis (
) y la curtosis (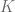 ), se define el estadístico de Jarque-Bera de la siguiente forma:
), se define el estadístico de Jarque-Bera de la siguiente forma:
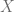 , digamos
, digamos  y
y 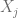 con
con 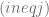 , la correlación entre dos
, la correlación entre dos 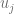 cualesquiera
cualesquiera 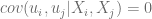 o, si X no es estocástica,
o, si X no es estocástica, 

 , de la forma:
, de la forma: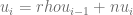
 y la hipótesis alternativa es
y la hipótesis alternativa es 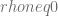 , para probar esta hipótesis se define el siguiente estadístico de prueba:
, para probar esta hipótesis se define el siguiente estadístico de prueba:
 (por Durbin-Watson). Entonces, considerando el coeficiente de correlación muestral de los residuos
(por Durbin-Watson). Entonces, considerando el coeficiente de correlación muestral de los residuos  , el estadístico de prueba
, el estadístico de prueba 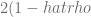 , por lo tanto, si este estadístico de prueba es igual a 2, esto implica que
, por lo tanto, si este estadístico de prueba es igual a 2, esto implica que  indicando que no existe correlación (serial) entre los residuos.
indicando que no existe correlación (serial) entre los residuos.
Debe estar conectado para enviar un comentario.