Una vez que hemos aprendido a calcular los intervalos de confianza podemos definir un entorno donde pudiera vivir nuestro parámetro poblacional, sin embargo, es necesario definir un elemento que nos permita usar este entorno para determinar si el planteamiento de nuestra investigación, se ajusta a la estimación que hemos hecho.
La idea básica de las pruebas de significancia es la de definir un estadístico de prueba y su distribución muestral según la hipótesis nula. La decisión de rechazar o no rechazar la hipótesis nula se toma con base en el valor del estadístico de prueba obtenido con los datos disponibles.
También pudiera interesarte
Prueba de significancia de los coeficientes de regresión: la prueba t
Con el supuesto de normalidad de , los estimadores de MCO y son en sí mismos normalmente distribuidos con sus medias y varianzas correspondientes. Por consiguiente, la variable
Sigue la distribución con grados de libertad. Si el valor del verdadero se especifica con la hipótesis nula, el valor se calcula fácilmente a partir de la muestra disponible y, por consiguiente, sirve como estadístico de prueba.
Y como este estadístico de prueba sigue una distribución , caben afirmaciones sobre los intervalos de confianza como la siguiente:
donde es el valor de que se plantea en la hipótesis nula y y son los valores de (los valores críticos de ) obtenidos de la tabla t para un nivel de significancia y grados de libertad.
Reescribiendo la inecuación involucrada, tenemos que
obteniendo así, el intervalo en el cual se encontrará con probabilidad , dado .
Calculamos los valores críticos en R usando la siguiente sintaxis:
En el lenguaje de pruebas de hipótesis, este intervalo de confianza a se conoce como la región de no rechazo (de la hipótesis nula ), y la región que queda fuera del intervalo de confianza conoce como región de rechazo (de la hipótesis nula ) o región crítica.
Los límites de confianza dados por los puntos extremos del intervalo de confianza se llaman también valores críticos.
Ahora se aprecia la estrecha conexión entre los enfoques de intervalo de confianza y prueba de significancia para realizar pruebas de hipótesis, pues al compararlos, tenemos que:
En el enfoque de intervalo de confianza se trata de establecer un rango o intervalo que tenga una probabilidad determinada de contener al verdadero aunque desconocido
En el enfoque de prueba de significancia se somete a hipótesis algún valor de y se ve si el estimador calculado se encuentra dentro de los límites (de confianza) razonables alrededor del valor sometido a hipótesis.
Sin embargo, en la práctica, no hay necesidad de estimar este intervalo explícitamente. Se calcula el valor de y se ve si cae entre los valores críticos o fuera de ellos y calculamos el valor de en R usando la siguiente sintaxis:
t.c <- (betai - H0.betai)/ee.betai
Ejemplo
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
Observación
Salario
Escolaridad
1
4.4567
6
2
5.77
7
3
5.9787
8
4
7.3317
9
5
7.3182
10
6
6.5844
11
7
7.8182
12
8
7.8351
13
9
11.0223
14
10
10.6738
15
11
10.8361
16
12
13.615
17
13
13.531
18
Tabla 3.2
Sabiendo que , y . Si consideramos , entonces .
Considerando la hipótesis nula y la hipótesis alternativa , calculamos los valores críticos en R usando la siguiente sintaxis:
Una vez ejecutadas estas instrucciones, obtenemos que
De forma gráfica, podemos expresar esta probabilidad así
Notamos entonces, que el valor está en la región de rechazo, por lo tanto, se rechaza la hipótesis nula .
Veamos ahora, qué es lo que ocurre con el valor que hemos calculado de . ¿Cae entre los valores críticos o fuera de ellos? . Calculamos el valor de en R usando la siguiente sintaxis:
En el siguiente gráfico, vemos con claridad que el valor se encuentra en la región crítica y la conclusión se mantiene; es decir, rechazamos .
En su pantalla debería aparecer:
Notas:
Observe que si el estimado es igual al hipotético, el valor será cero. Por otra parte, a la medida en que el valor de estimado se aleje del valor hipotético de , el será cada vez mayor. Por consiguiente, un valor grande de nos permite rechazar la hipótesis nula con mayor confianza.
En la práctica, se plantea la hipótesis nula (con énfasis en ) pues al rechazar esta hipótesis, podemos asegurar con cierto grado de confianza, que y así, concluir que la variable que acompaña a explica a la variable dependiente.
Una vez que hemos calculado los estimadores de la Función de Regresión Muestral, es decir, y sabiendo que estos cálculos están basados en una muestra, debemos ser cautelosos con las afirmaciones que derivan a partir de dichos estimadores, es por esto que debemos determinar una forma de medir qué tan confiables son estos cálculos.
También pudiera interesarte
¿Qué es un intervalo de confianza?
Habiendo definido el error estándar como una herramienta para medir qué tan precisos son nuestros estimadores, resulta intuitivo, definir un entorno en el que viven nuestros estimadores basado en el error estándar. Generalmente, esto se hace considerando intervalos centrados en el estimador de longitud igual a dos, cuatro y hasta seis veces el error estándar, esperando que este intervalo contenga el verdadero parámetro (de la Función de Regresión Poblacional) con un cierto grado de confianza.
Recordando que al contar únicamente con muestras, los verdaderos parámetros de la Función de Regresión Poblacional son desconocidos, consideremos particularmente, que queremos determinar qué tan cerca está el estimador del verdadero parámetro $\beta_i$, para esto se consideran dos números positivos y () de modo que la probabilidad de que el intervalo aleatorio contenga al verdadero sea igual a , es decir,
A partir de esta igualdad podemos identificar algunos elementos:
es el intervalo de confianza y este intervalo pudiera no contener al verdadero valor.
Los extremos del intervalo de confianza se conocen como límites de confianza, donde es el límite de confianza inferior y es el límite de confianza superior.
es el coeficiente de confianza, en la práctica, suele expresarse en forma porcentual como .
es el nivel de significancia, en la práctica, suele expresarse en forma porcentual como .
El nivel de significancia también es conocido como la probabilidad de cometer un error tipo I. Recordando que
un error tipo I consiste en rechazar una hipótesis verdadera
un error tipo II consiste en no rechazar una hipótesis falsa.
En el primer panel se lee: Usted está embarazado. En el segundo panel se lee: Usted no está embaraza.
Intervalos de confianza de los estimadores
Considerando el supuesto de que los residuos siguen una distribución normal, podemos concluir que los estimadores de Mínimos Cuadrados Ordinarios y son en sí mismos normalmente distribuidos con sus medias y varianzas correspondientes. Sabiendo esto, podemos definir una variable distribuida normalmente con media cero y varianza igual a uno, de la siguiente forma:
Así, se puede utilizar la distribución normal para hacer afirmaciones probabilísticas sobre , siempre que se conozca la verdadera varianza poblacional .
Si se conoce , una propiedad importante de una variable normalmente distribuida con media y varianza es que el área bajo la curva normal entre es cercana a 68%, que entre es alrededor de 95%, y que entre los límites el área es cercana a 99.7%.
Pero pocas veces se conoce el verdadero valor de y, en la práctica, está determinada por el estimador insesgado . Entonces, si en nuestra variable estandarizada Z, se reemplaza por , tenemos que
Es posible demostrar que la variable , así definida, sigue la distribución con grados de libertad. Por consiguiente, en lugar de utilizar la distribución normal, se puede utilizar la distribución para construir un intervalo de confianza para de la siguiente forma:
donde es el valor de la variable obtenida de la distribución para un nivel de significancia de y grados de libertad; a menudo se denomina el valor crítico a un nivel de significancia .
Considerando , podemos considerar el siguiente intervalo de confianza.
Intervalo de confianza para
Considerando la ecuación
Podemos manipular algebraicamente, para obtener que
Esta ecuación proporciona un intervalo de confianza para de , que se escribe en forma más compacta como
Calculamos los límites de confianza en R usando la siguiente sintaxis:
Considerando el supuesto de que los residuos siguen una distribución normal, podemos concluir que la variable
sigue la distribución con grados de libertad. Por lo tanto, con la distribución se establece el intervalo de confianza para
Donde y son dos valores de (los valores críticos ) obtenidos de la tabla chi cuadrado para grados de libertad de manera que ellos cortan de las áreas de las colas de la distribución .
Sustituyendo por y operando algebraicamente en la inecuación, tenemos que
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
Observación
Salario
Escolaridad
1
4.4567
6
2
5.77
7
3
5.9787
8
4
7.3317
9
5
7.3182
10
6
6.5844
11
7
7.8182
12
8
7.8351
13
9
11.0223
14
10
10.6738
15
11
10.8361
16
12
13.615
17
13
13.531
18
Tabla 3.2
Una vez que hemos calculado el modelo lineal que define este conjunto de datos y en consecuencia, los parámetros estimados. Con un nivel de significancia de 5%, es decir, , podemos calcular los intervalos de confianza de ambos estimadores y además, el intervalo de confianza de la desviación estándar estimada, para esto, usamos la siguiente sintaxis:
# Nivel de Significancia
alpha <- 0.05
# Intervalo de Confianza de beta2
li.beta2 <- beta2 - qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.beta2
ls.beta2 <- beta2 + qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.beta2
# Intervalo de Confianza de beta1
li.beta1 <- beta1 - qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.beta1
ls.beta1 <- beta1 + qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.beta1
# Intervalo de Confianza de sigma2
li.sigma2 <- (length(escolaridad)-2)*sigma2.e/qchisq(alpha/2,df=length(escolaridad)-2,lower.tail=F)
ls.sigma2 <- (length(escolaridad)-2)*sigma2.e/qchisq(1-alpha/2,df=length(escolaridad)-2,lower.tail=F)
Al ejecutar estas instrucciones obtenemos que el intervalo de confianza del parámetro es igual a
y por lo tanto, concluimos que la probabilidad de que el intervalo (aleatorio) que allí aparece incluya al verdadero es de 0.95,
Al ejecutar estas instrucciones obtenemos que el intervalo de confianza del parámetro es igual a
y por lo tanto, concluimos que la probabilidad de que el intervalo (aleatorio) que allí aparece incluya al verdadero es de 0.95.
Al ejecutar estas instrucciones obtenemos que el intervalo de confianza del parámetro es igual a
y por lo tanto, concluimos que la probabilidad de que el intervalo (aleatorio) que allí aparece incluya al verdadero es de 0.95.


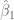


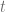


![P \left[ -t_{\alpha/2} \leq \dfrac{\hat{\beta}_i - \beta^*_i}{ee(\hat{\beta}_i)} \leq t_{\alpha/2} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+-t_%7B%5Calpha%2F2%7D+%5Cleq+%5Cdfrac%7B%5Chat%7B%5Cbeta%7D_i+-+%5Cbeta%5E%2A_i%7D%7Bee%28%5Chat%7B%5Cbeta%7D_i%29%7D+%5Cleq+t_%7B%5Calpha%2F2%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
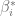
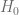


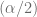
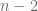
![P \left[ \beta^*_i - t_{\alpha/2} ee(\hat{\beta}_i) \leq \hat{\beta}_i \leq \beta^*_i + t_{\alpha/2} ee(\hat{\beta}_i) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Cbeta%5E%2A_i+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cleq++%5Chat%7B%5Cbeta%7D_i++%5Cleq+%5Cbeta%5E%2A_i+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)

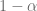

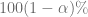

![P \left[ \hat{\beta}_i - t_{\alpha/2} ee(\hat{\beta}_i) \leq \beta_i \leq \hat{\beta}_i + t_{\alpha/2} ee(\hat{\beta}_i) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Chat%7B%5Cbeta%7D_i+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cleq+%5Cbeta_i+%5Cleq+%5Chat%7B%5Cbeta%7D_i+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
![P \left[ \beta^*_i - t_{\alpha/2} ee(\hat{\beta}_i) \leq \hat{\beta}_i \leq \beta^*_i + t_{\alpha/2} ee(\hat{\beta}_i) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Cbeta%5E%2A_i+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cleq+%5Chat%7B%5Cbeta%7D_i++%5Cleq+%5Cbeta%5E%2A_i+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_i%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)

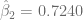


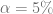

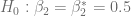



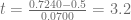




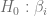



 y
y 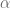 (
(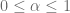 ) de modo que la probabilidad de que el intervalo aleatorio
) de modo que la probabilidad de que el intervalo aleatorio  contenga al verdadero
contenga al verdadero  , es decir,
, es decir,
 es el límite de confianza inferior y
es el límite de confianza inferior y 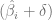 es el límite de confianza superior.
es el límite de confianza superior.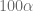 .
.
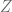 distribuida normalmente con media cero y varianza igual a uno, de la siguiente forma:
distribuida normalmente con media cero y varianza igual a uno, de la siguiente forma:
 .
.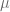 y varianza
y varianza  es cercana a 68%, que entre
es cercana a 68%, que entre  es alrededor de 95%, y que entre los límites
es alrededor de 95%, y que entre los límites  el área es cercana a 99.7%.
el área es cercana a 99.7%.


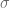 por
por  , tenemos que
, tenemos que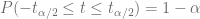
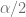 y
y 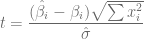 , podemos considerar el siguiente intervalo de confianza.
, podemos considerar el siguiente intervalo de confianza.![P \left[ -t_{\alpha/2} \leq \dfrac{\hat{\beta}_i - \beta_i}{ee(\hat{\beta}_i)} \leq t_{\alpha/2} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+-t_%7B%5Calpha%2F2%7D+%5Cleq+%5Cdfrac%7B%5Chat%7B%5Cbeta%7D_i+-+%5Cbeta_i%7D%7Bee%28%5Chat%7B%5Cbeta%7D_i%29%7D+%5Cleq+t_%7B%5Calpha%2F2%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
![P \left[ -t_{\alpha/2} \leq \dfrac{\hat{\beta}_2 - \beta_2}{ee(\hat{\beta}_2)} \leq t_{\alpha/2} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+-t_%7B%5Calpha%2F2%7D+%5Cleq+%5Cdfrac%7B%5Chat%7B%5Cbeta%7D_2+-+%5Cbeta_2%7D%7Bee%28%5Chat%7B%5Cbeta%7D_2%29%7D+%5Cleq+t_%7B%5Calpha%2F2%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
![P \left[ \hat{\beta}_2 - t_{\alpha/2} ee(\hat{\beta}_2) \leq \beta_2 \leq \hat{\beta}_2 + t_{\alpha/2} ee(\hat{\beta}_2) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Chat%7B%5Cbeta%7D_2+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_2%29+%5Cleq+%5Cbeta_2+%5Cleq+%5Chat%7B%5Cbeta%7D_2+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_2%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
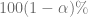 , que se escribe en forma más compacta como
, que se escribe en forma más compacta como
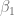
![P \left[ -t_{\alpha/2} \leq \dfrac{\hat{\beta}_1 - \beta_1}{ee(\hat{\beta}_1)} \leq t_{\alpha/2} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+-t_%7B%5Calpha%2F2%7D+%5Cleq+%5Cdfrac%7B%5Chat%7B%5Cbeta%7D_1+-+%5Cbeta_1%7D%7Bee%28%5Chat%7B%5Cbeta%7D_1%29%7D+%5Cleq+t_%7B%5Calpha%2F2%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
![P \left[ \hat{\beta}_1 - t_{\alpha/2} ee(\hat{\beta}_1) \leq \beta_1 \leq \hat{\beta}_1 + t_{\alpha/2} ee(\hat{\beta}_1) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Chat%7B%5Cbeta%7D_1+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_1%29+%5Cleq+%5Cbeta_1+%5Cleq+%5Chat%7B%5Cbeta%7D_1+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_1%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)


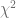 con
con 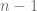 grados de libertad. Por lo tanto, con la distribución
grados de libertad. Por lo tanto, con la distribución 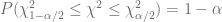
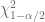 y
y  son dos valores de
son dos valores de  de las áreas de las colas de la distribución
de las áreas de las colas de la distribución 
 y operando algebraicamente en la inecuación, tenemos que
y operando algebraicamente en la inecuación, tenemos que![P \left[ (n-2) \dfrac{\hat{\sigma}^2}{\chi^2_{\alpha/2}} \leq \sigma^2 \leq (n-2) \dfrac{\hat{\sigma}^2}{\chi^2_{1-\alpha/2}} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%28n-2%29+%5Cdfrac%7B%5Chat%7B%5Csigma%7D%5E2%7D%7B%5Cchi%5E2_%7B%5Calpha%2F2%7D%7D+%5Cleq+%5Csigma%5E2+%5Cleq+%28n-2%29+%5Cdfrac%7B%5Chat%7B%5Csigma%7D%5E2%7D%7B%5Cchi%5E2_%7B1-%5Calpha%2F2%7D%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
 para
para 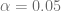 , podemos calcular los intervalos de confianza de ambos estimadores y además, el intervalo de confianza de la
, podemos calcular los intervalos de confianza de ambos estimadores y además, el intervalo de confianza de la 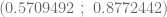



Debe estar conectado para enviar un comentario.