
Una vez que hemos calculado los estimadores de la Función de Regresión Muestral, es decir, 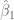

También pudiera interesarte
¿Qué es un intervalo de confianza?
Habiendo definido el error estándar como una herramienta para medir qué tan precisos son nuestros estimadores, resulta intuitivo, definir un entorno en el que viven nuestros estimadores basado en el error estándar. Generalmente, esto se hace considerando intervalos centrados en el estimador de longitud igual a dos, cuatro y hasta seis veces el error estándar, esperando que este intervalo contenga el verdadero parámetro (de la Función de Regresión Poblacional) con un cierto grado de confianza.
Recordando que al contar únicamente con muestras, los verdaderos parámetros de la Función de Regresión Poblacional son desconocidos, consideremos particularmente, que queremos determinar qué tan cerca está el estimador 
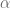
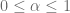




A partir de esta igualdad podemos identificar algunos elementos:
Los extremos del intervalo de confianza se conocen como límites de confianza, donde 
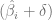
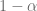
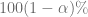
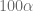
El nivel de significancia también es conocido como la probabilidad de cometer un error tipo I. Recordando que
- un error tipo I consiste en rechazar una hipótesis verdadera
- un error tipo II consiste en no rechazar una hipótesis falsa.

En el segundo panel se lee: Usted no está embaraza.
Intervalos de confianza de los estimadores
Considerando el supuesto de que los residuos 

Así, se puede utilizar la distribución normal para hacer afirmaciones probabilísticas sobre 
Si se conoce 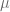






Pero pocas veces se conoce el verdadero valor de 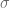


Es posible demostrar que la variable 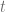
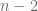
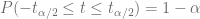
donde 
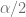
Considerando 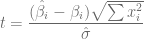
![P \left[ -t_{\alpha/2} \leq \dfrac{\hat{\beta}_i - \beta_i}{ee(\hat{\beta}_i)} \leq t_{\alpha/2} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+-t_%7B%5Calpha%2F2%7D+%5Cleq+%5Cdfrac%7B%5Chat%7B%5Cbeta%7D_i+-+%5Cbeta_i%7D%7Bee%28%5Chat%7B%5Cbeta%7D_i%29%7D+%5Cleq+t_%7B%5Calpha%2F2%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
Intervalo de confianza para 
Considerando la ecuación
![P \left[ -t_{\alpha/2} \leq \dfrac{\hat{\beta}_2 - \beta_2}{ee(\hat{\beta}_2)} \leq t_{\alpha/2} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+-t_%7B%5Calpha%2F2%7D+%5Cleq+%5Cdfrac%7B%5Chat%7B%5Cbeta%7D_2+-+%5Cbeta_2%7D%7Bee%28%5Chat%7B%5Cbeta%7D_2%29%7D+%5Cleq+t_%7B%5Calpha%2F2%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
Podemos manipular algebraicamente, para obtener que
![P \left[ \hat{\beta}_2 - t_{\alpha/2} ee(\hat{\beta}_2) \leq \beta_2 \leq \hat{\beta}_2 + t_{\alpha/2} ee(\hat{\beta}_2) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Chat%7B%5Cbeta%7D_2+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_2%29+%5Cleq+%5Cbeta_2+%5Cleq+%5Chat%7B%5Cbeta%7D_2+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_2%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
Esta ecuación proporciona un intervalo de confianza para 
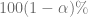

Calculamos los límites de confianza en R usando la siguiente sintaxis:
li.beta2 <- beta2 - qt(1-alpha/2, df=length(X)-2)*ee.beta2
ls.beta2 <- beta2 - qt(1-alpha/2, df=length(X)-2)*ee.beta2Intervalo de confianza para 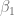
Considerando la ecuación
![P \left[ -t_{\alpha/2} \leq \dfrac{\hat{\beta}_1 - \beta_1}{ee(\hat{\beta}_1)} \leq t_{\alpha/2} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+-t_%7B%5Calpha%2F2%7D+%5Cleq+%5Cdfrac%7B%5Chat%7B%5Cbeta%7D_1+-+%5Cbeta_1%7D%7Bee%28%5Chat%7B%5Cbeta%7D_1%29%7D+%5Cleq+t_%7B%5Calpha%2F2%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
Podemos manipular algebraicamente, para obtener que
![P \left[ \hat{\beta}_1 - t_{\alpha/2} ee(\hat{\beta}_1) \leq \beta_1 \leq \hat{\beta}_1 + t_{\alpha/2} ee(\hat{\beta}_1) \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%5Chat%7B%5Cbeta%7D_1+-+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_1%29+%5Cleq+%5Cbeta_1+%5Cleq+%5Chat%7B%5Cbeta%7D_1+%2B+t_%7B%5Calpha%2F2%7D+ee%28%5Chat%7B%5Cbeta%7D_1%29+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
Esta ecuación proporciona un intervalo de confianza para

Calculamos los límites de confianza en R usando la siguiente sintaxis:
li.beta1 <- beta1 - qt(1-alpha/2, df=length(X)-2)*ee.beta1
ls.beta1 <- beta1 - qt(1-alpha/2, df=length(X)-2)*ee.beta1Intervalo de confianza para
Considerando el supuesto de que los residuos

sigue la distribución 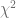
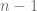
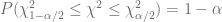
Donde 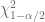



Sustituyendo 
![P \left[ (n-2) \dfrac{\hat{\sigma}^2}{\chi^2_{\alpha/2}} \leq \sigma^2 \leq (n-2) \dfrac{\hat{\sigma}^2}{\chi^2_{1-\alpha/2}} \right] = 1-\alpha](https://s0.wp.com/latex.php?latex=P+%5Cleft%5B+%28n-2%29+%5Cdfrac%7B%5Chat%7B%5Csigma%7D%5E2%7D%7B%5Cchi%5E2_%7B%5Calpha%2F2%7D%7D+%5Cleq+%5Csigma%5E2+%5Cleq+%28n-2%29+%5Cdfrac%7B%5Chat%7B%5Csigma%7D%5E2%7D%7B%5Cchi%5E2_%7B1-%5Calpha%2F2%7D%7D+%5Cright%5D+%3D+1-%5Calpha&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
que da el intervalo de confianza a 
li.var <- (n-2)*sigma2.e/qchisq(alpha/2,df=length(X)-2)
ls.var <- (n-2)*sigma2.e/qchisq(1-alpha/2,df=length(X)-2)Ejemplo
Consideremos un pequeño conjunto de datos, particularmente, los datos que se encuentran en la Tabla 3.2 del libro de Econometría de Damodar N. Gujarati and Dawn Porter en su quinta edición. Este conjunto de datos proporciona los datos primarios que se necesitan para estimar el efecto cuantitativo de la escolaridad en los salarios:
| Observación | Salario | Escolaridad |
| 1 | 4.4567 | 6 |
| 2 | 5.77 | 7 |
| 3 | 5.9787 | 8 |
| 4 | 7.3317 | 9 |
| 5 | 7.3182 | 10 |
| 6 | 6.5844 | 11 |
| 7 | 7.8182 | 12 |
| 8 | 7.8351 | 13 |
| 9 | 11.0223 | 14 |
| 10 | 10.6738 | 15 |
| 11 | 10.8361 | 16 |
| 12 | 13.615 | 17 |
| 13 | 13.531 | 18 |
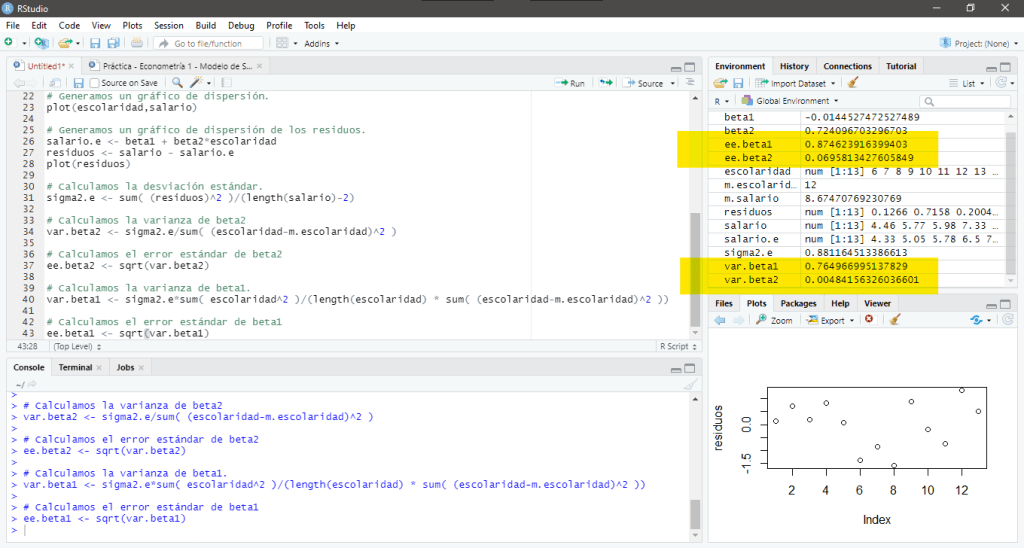
Una vez que hemos calculado el modelo lineal que define este conjunto de datos y en consecuencia, los parámetros estimados. Con un nivel de significancia de 5%, es decir, 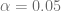
# Nivel de Significancia
alpha <- 0.05
# Intervalo de Confianza de beta2
li.beta2 <- beta2 - qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.beta2
ls.beta2 <- beta2 + qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.beta2
# Intervalo de Confianza de beta1
li.beta1 <- beta1 - qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.beta1
ls.beta1 <- beta1 + qt(alpha/2, df=length(escolaridad)-2,lower.tail=F)*ee.beta1
# Intervalo de Confianza de sigma2
li.sigma2 <- (length(escolaridad)-2)*sigma2.e/qchisq(alpha/2,df=length(escolaridad)-2,lower.tail=F)
ls.sigma2 <- (length(escolaridad)-2)*sigma2.e/qchisq(1-alpha/2,df=length(escolaridad)-2,lower.tail=F)Al ejecutar estas instrucciones obtenemos que el intervalo de confianza del parámetro
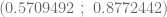
y por lo tanto, concluimos que la probabilidad de que el intervalo (aleatorio) que allí aparece incluya al verdadero
Al ejecutar estas instrucciones obtenemos que el intervalo de confianza del parámetro

y por lo tanto, concluimos que la probabilidad de que el intervalo (aleatorio) que allí aparece incluya al verdadero
Al ejecutar estas instrucciones obtenemos que el intervalo de confianza del parámetro
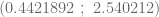
y por lo tanto, concluimos que la probabilidad de que el intervalo (aleatorio) que allí aparece incluya al verdadero
En su pantalla debería aparecer:

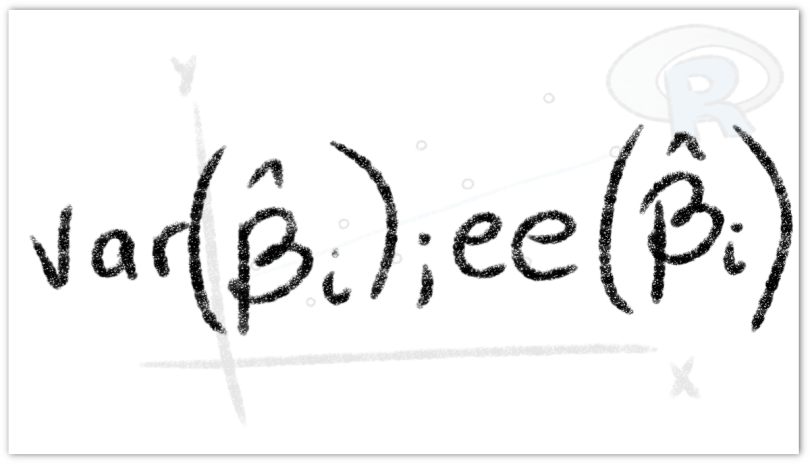

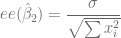



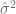 se conoce como el error estándar de estimación o el error estándar de la regresión (eee). No es más que la desviación estándar de los valores
se conoce como el error estándar de estimación o el error estándar de la regresión (eee). No es más que la desviación estándar de los valores  alrededor de la línea de regresión estimada, la cual suele servir como medida para resumir la bondad del ajuste de dicha línea. Se calcula de la siguiente manera
alrededor de la línea de regresión estimada, la cual suele servir como medida para resumir la bondad del ajuste de dicha línea. Se calcula de la siguiente manera

Debe estar conectado para enviar un comentario.